
El Archivo Robots.txt en un Servidor Web
Una manera de empezar a entender aquello ejecutándose sobre un servidor web, es visualizar el archivo de nombre “robots.txt” en el servidor. El archivo “robots.txt” es un listado de directorios y archivos en el servidor web, los cuales el propietario desea sean omitidos por los “web crawlers” del proceso de indexación. Un “web crawler” es una pieza de software el cual se utiliza para catalogar información web a ser utilizada por los motores de búsqueda y archivos, los cuales comúnmente son desplegados por motores de búsqueda como Google o Bing. Estos “web crawlers” recorren Internet e indexan (archivan) todos los posibles hallazgos para mejorar la precisión y velocidad en la funcionalidad de búsqueda de Internet.
Para un atacante malicioso, el archivo “robots.txt” es una hoja de ruta para identificar información sensible, porque cualquier archivo “robots.txt” del servidor web puede ser obtenida con una simple petición del navegador.
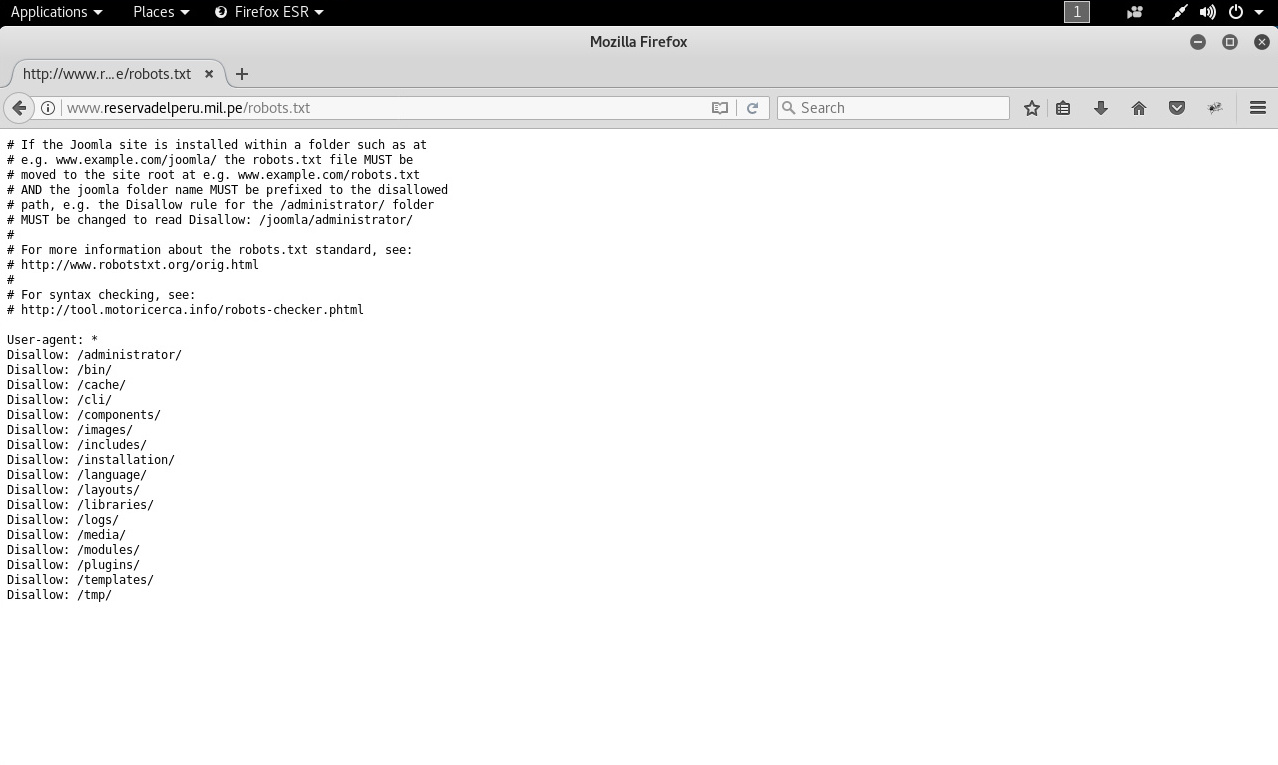
Al revisar los contenidos de este archivo “robots.txt” se expone la utilización de Joomla.
También es factible obtener el archivo “robots.txt” haciendo uso de la herramienta “wget” en Linux.
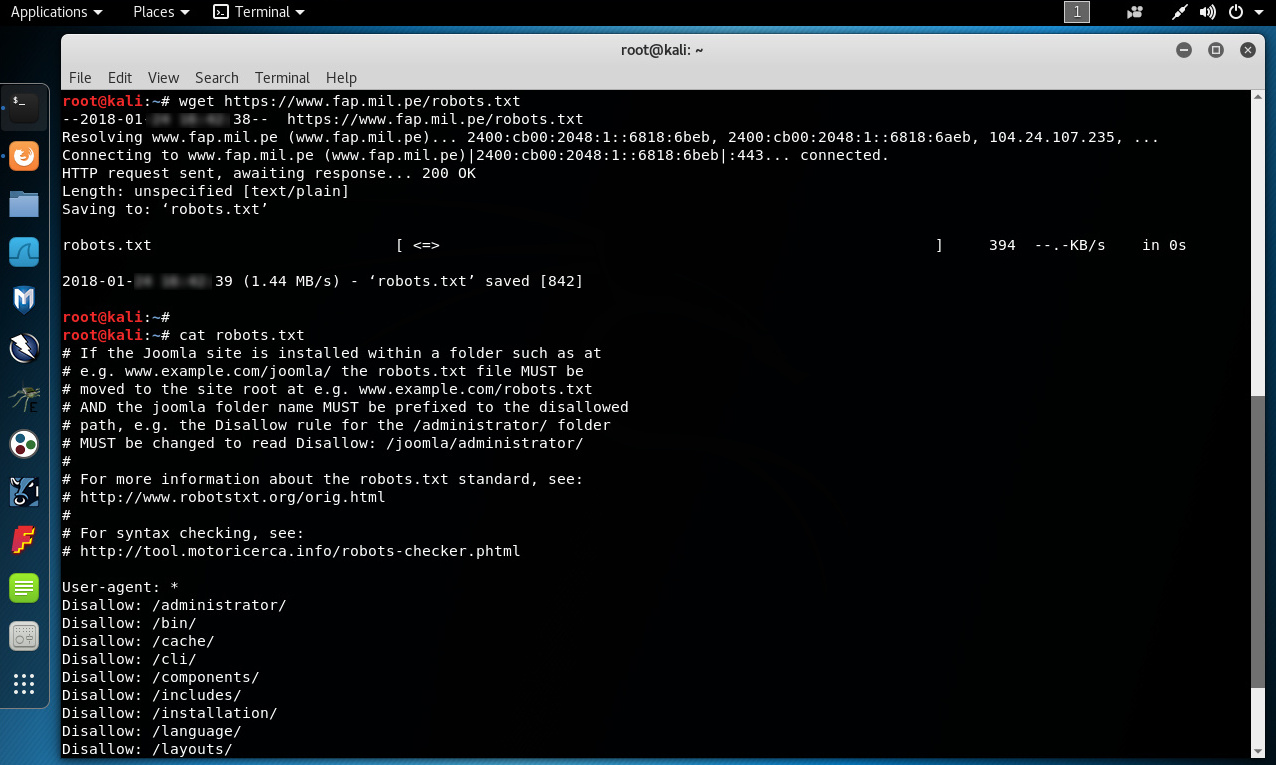
Al revisar este segundo archivo “robots.txt”, también se expone la utilización de Joomla.
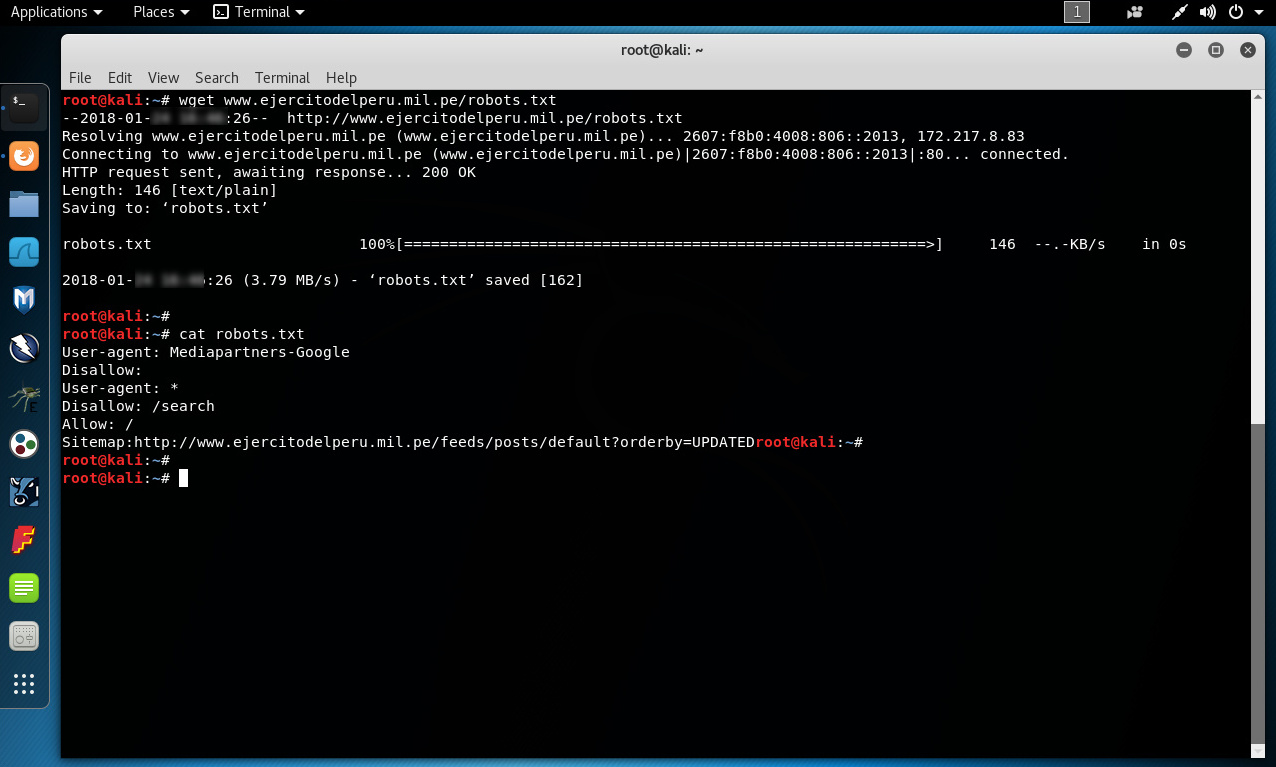
Al obtener un tercer archivo “robots.txt” se visualiza una línea “sitemap”. Dado el hecho los motores de búsqueda inician haciendo un “crawling” del sitio verificando el archivo “robots.txt”, esto proporciona una oportunidad de notificarlos sobre la existencia de un “XML sitemap”.
El archivo “robots.txt” esta divido en cuatro diferentes secciones; directorios; archivos; rutas (URLS limpias), y rutas (URLs no limpias).
Las URLs limpias son rutas URLs absolutas las cuales se pueden copiar y pegar dentro del navegador web. Las rutas con URLs no limpias están utilizando un parámetro para direccionar la funcionalidad de una página. Esto implica utilizar una página para obtener datos basándose únicamente en los parámetros pasados en la URL. Directorios y archivos son muy sencillos y se explican solos.
Cada servidor web debe tener un archivo “robots.txt” en su directorio raíz, de otra manera los “web crawlers” indexarán el sitio web completo, incluyendo bases de datos, archivos, y todo. Aquellos ítemes los cuales el administrador no desea sean parte de la siguiente búsqueda en Google deben ser incluidos aquí. El directorio raíz de un servidor web es un directorio físico en una computadora, donde está instalado el software para el servidor web. En Windows, el directorio web es usualmente “C:/inetpub/wwwroot/”. Y en Linux puede ser una variante a “/var/www/”.
No existe nada para detener la creación de un “web crawler” el cual proporcione la funcionalidad opuesta. Una herramienta podría, si se desea, únicamente solicitar y obtener los ítemes incluidos e el archivo “robots.txt”, y podría ahorrar un tiempo substancial si se está realizando un reconocimiento a diversos servidores web. De otro lado, se puede manualmente solicitar y revisar cada archivo “robots.txt” en el navegador. El archivo “robots.txt” es una barricada completa para los “web crawlers” automáticos, pero no para los atacantes maliciosos quienes desean revisar esta información sensible.
Fuentes:
http://www.robotstxt.org/
https://technicalseo.com/crawl-indexation/directives/robots-txt/
https://www.joomla.org/
https://www.gnu.org/software/wget/manual/wget.html
Sobre el Autor

Alonso Eduardo Caballero Quezada - ReYDeS
Instructor y Consultor Independiente en Ciberseguridad
Correo Electrónico: ReYDeS@gmail.com
Twitter: https://twitter.com/Alonso_ReYDeS
LinkedIn: https://pe.linkedin.com/in/alonsocaballeroquezada/
Facebook: https://www.facebook.com/alonsoreydes
Youtube: https://www.youtube.com/c/AlonsoCaballero
