
Realizar un Spidering Web utilizando Zed Attack Proxy
El “Spider” o Araña es una herramienta utilizada para automatizar el descubrimiento de nuevos recursos (URLs) sobre un sitio en particular. Inicia con una lista de URLs para visitar, denominada las semillas, que depende de la forma en como se iniciará el Spider. El Spider luego visita estas URLs identificando todos los hiperenlaces en la página y los añade a la lista de URLs para visitar, además este proceso continúa de manera recursiva tanto como sean encontrados nuevo recursos.
Existen cuatro métodos para iniciar el Spider, diferenciados por la lista semilla con el cual inicia.
- Spider Site o Spider del Sitio - La lista semilla contiene todas las URIs existentes ya encontradas para el sitio seleccionado.
- Spider Subtree o Spider a Rama - La lista semilla contiene todas las URIs existentes ya encontradas y presentes en la rama de un nodo seleccionado.
- Spider URL o Spider URL - La lista semilla contiene únicamente la URI correspondiente al nodo seleccionado (en el árbol del sitio).
- Spider all in Scope o Spider todo en Alcance - La lista semilla contiene todas las URIs que el usuario ha seleccionado como “En Alcance”.
- Spider all in Context... o Spider todo en Contexto... - La lista semilla contiene todas las URIs seleccionadas por el usuario como en el contexto seleccionado.
Durante el procesamiento de una URL, el Spider realiza una petición para traer el recurso y luego interpretar la respuesta, identificando hiperenlaces. Actualmente tiene el siguiente comportamiento cuando procesa tipos de respuestas:
HTML
Procesa etiquetas específicas, identificando enlaces a nuevos recursos:
- Base - Manejo adecuado
- A, Link, Area - Atributo “href”
- Frame, Iframe, Script, Img - Atributo “src”
- Meta - “http-equiv” para “location” y “refresh”
- Form - Manejo adecuado para Formularios con los método GET y POST. Los valores de los campos son generados válidamente, incluyendo tipos de entrada HTML 5.0
- Comments - Etiquetas válidas en los comentarios también son analizados, si se especifica en la pantalla de opciones del Spider.
Archivo Robots.txt
Si está ajustado en la pantalla de opciones del Spider, también se analiza el archivo “Robots.txt” y se intenta identificar nuevos recursos utilizando las reglas especificadas. Se tiene que mencionar que el Spider no sigue las reglas especificadas dentro del archivo “Robots.txt”.
OData Atom format
Contenido OData utilizando el formato Atom es actualmente soportado. Todos los enlaces incluidos (relativo o absoluto) son procesados.
Non-HML Text Response
Las respuesta de texto son interpretadas escaneandolas por patrones URL.
Non-Text Response
Actualmente, el Spider de ZAP no proceso este tipo de recursos.
Otros Aspectos
- Cuando se verifica si una URL ha sido ya visitada, el comportamiento relacionado a como los parámetros son manejados puede ser configurado sobre la pantalla Opciones del Spider.
- Cuando se verifica si una URL ha sido ya visitada, hay pocos parámetros los cuales son ignorados: jsessionid, phpsessid, aspsessionid, utm_*.
- El comportamiento del Spider relacionado a la cookies se define mediante la opción presente en “Edit -> Enable Session Tracking” o “Editar -> Habilitar Rastreo de Sesión”. Si esta opción esta habilitada, el Spider manejará adecuadamente cualquier cookie recibida desde el servidor y lo enviará de vuelta. Si la opción está deshabilitada, el Spider no enviará ninguna cookie en estas peticiones.
Se inicia ZAP, para luego configurar su utilización con el navegador web Firefox .
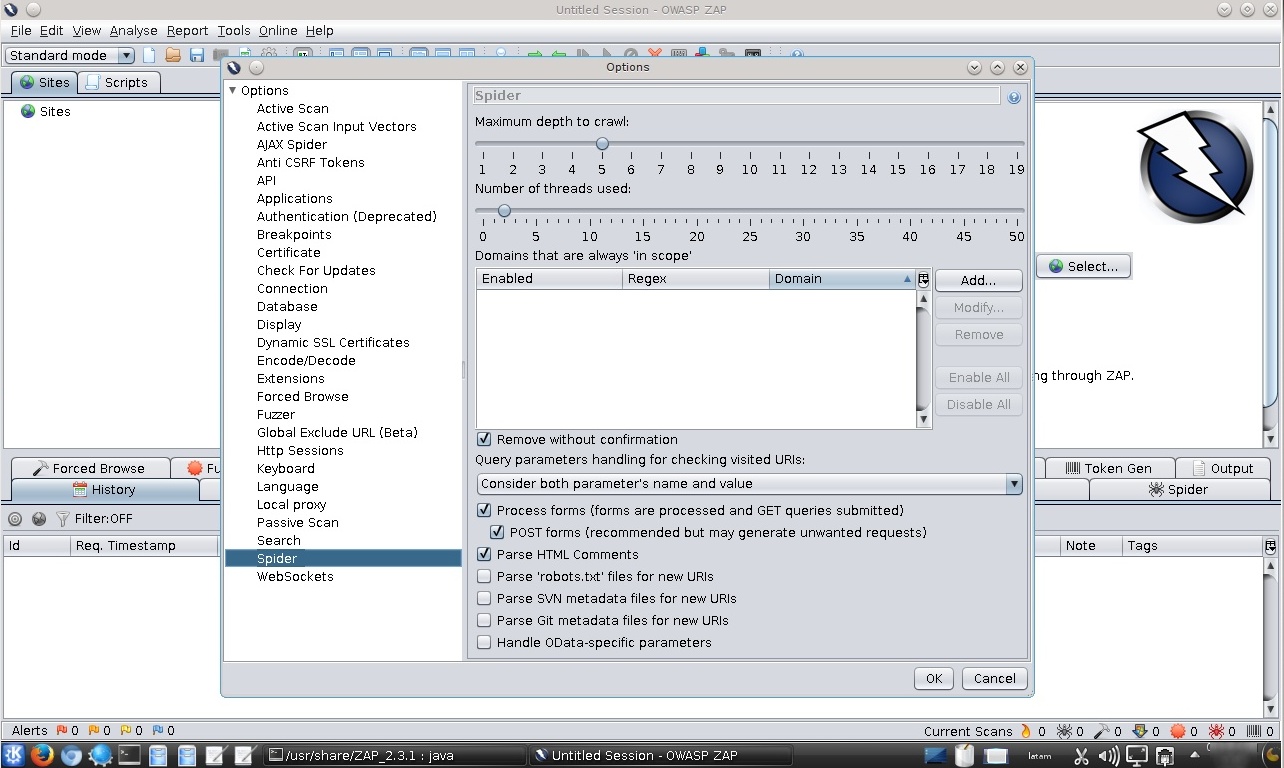
Para visualizar y modificar la configuración del Spider ingresar al menú “Edit -> Options -> Spider” o Editar -> Opciones -> Araña. Para el ejemplo se activará la opción “Parse 'robots.txt' files for new URIs”. Además de ello se puede configurar, la profundidad máxima, el número de hilos, los dominios en el “alcance”, etc.
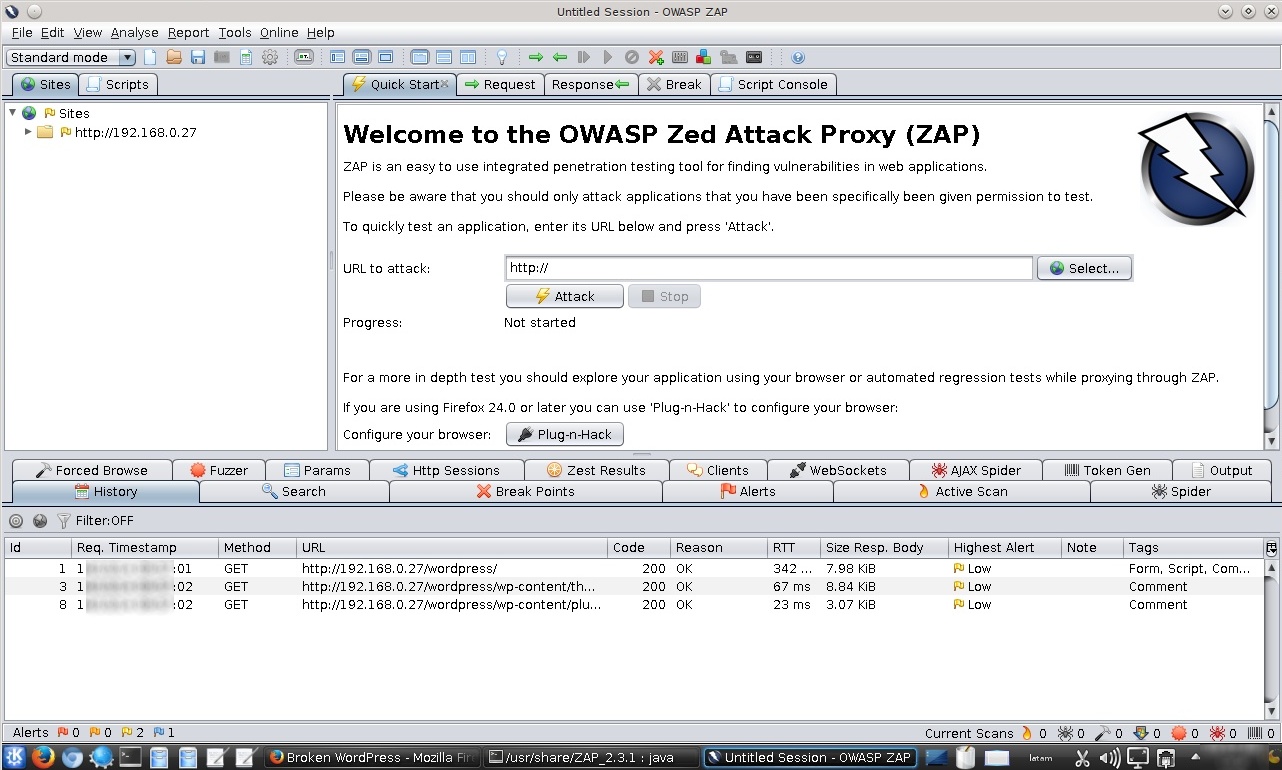
Se ingresa a la aplicación web en evaluación.
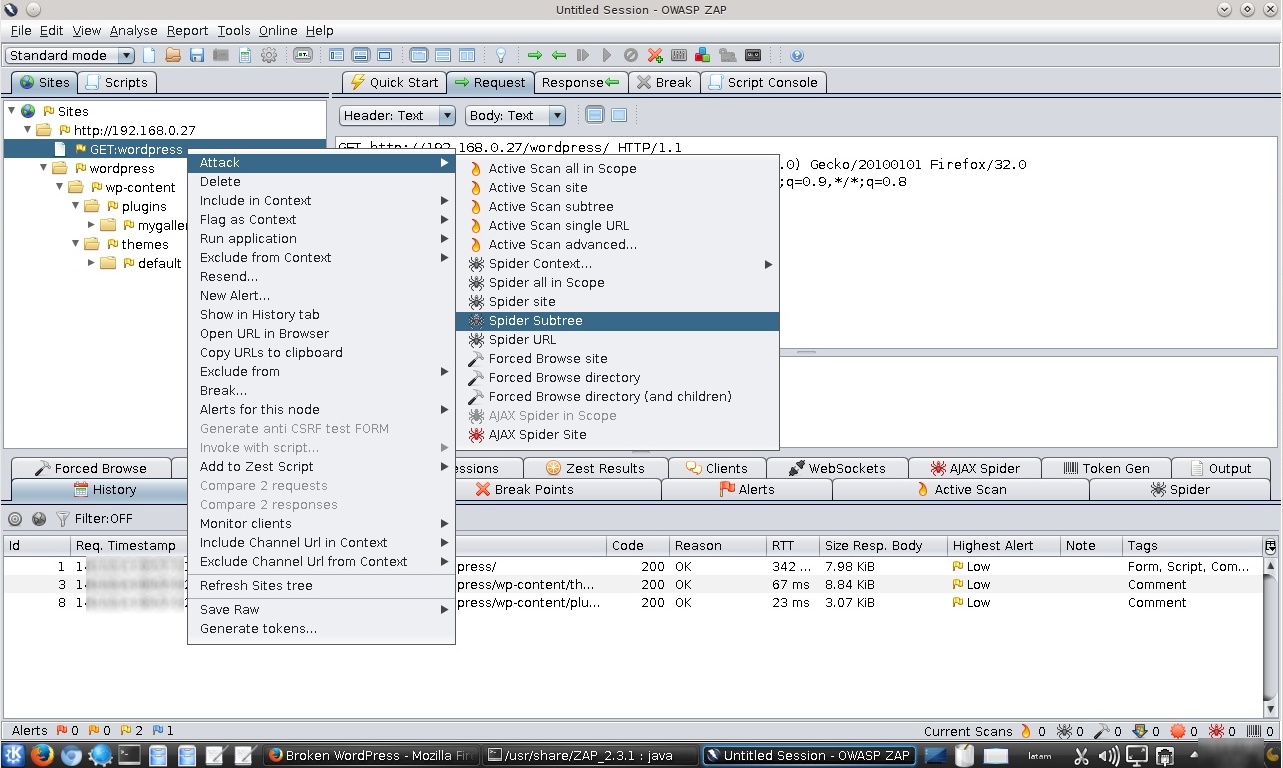
Hacer clic derecho sobre la selección pertinente , para luego seleccionar la opción “Attack -> Spider Subtree” o “Ataque -> Araña a la Rama”.
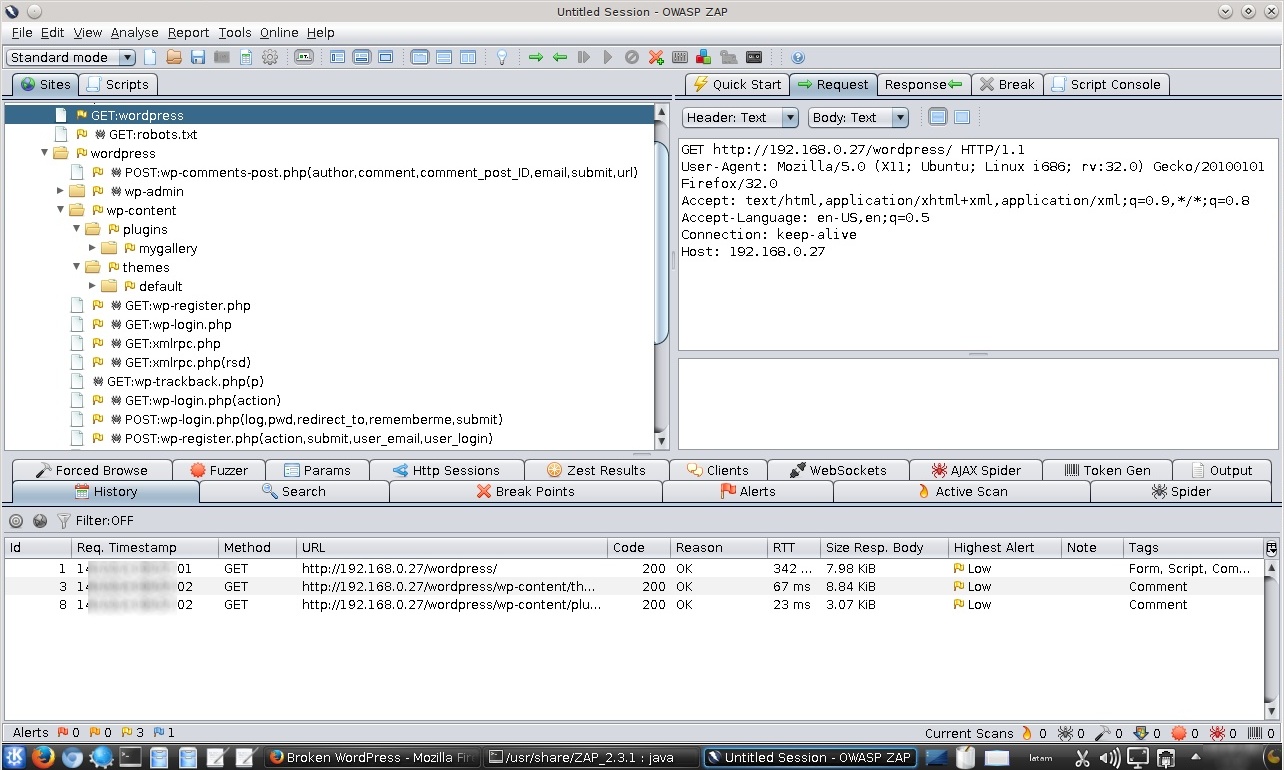
Notar como se ha poblado en panel superior izquierdo con nuevos recursos encontrados.
Al hacer clic en la pestaña de nombre “Spider” ubicado en el panel inferior, se visualizan las columnas sobre los recursos procesados, el método utilizado, la URI y “Flags” o Banderas, en esta última columna anotar el texto “SEED” o semilla, indicador de que este dato se incluye en la lista semilla.
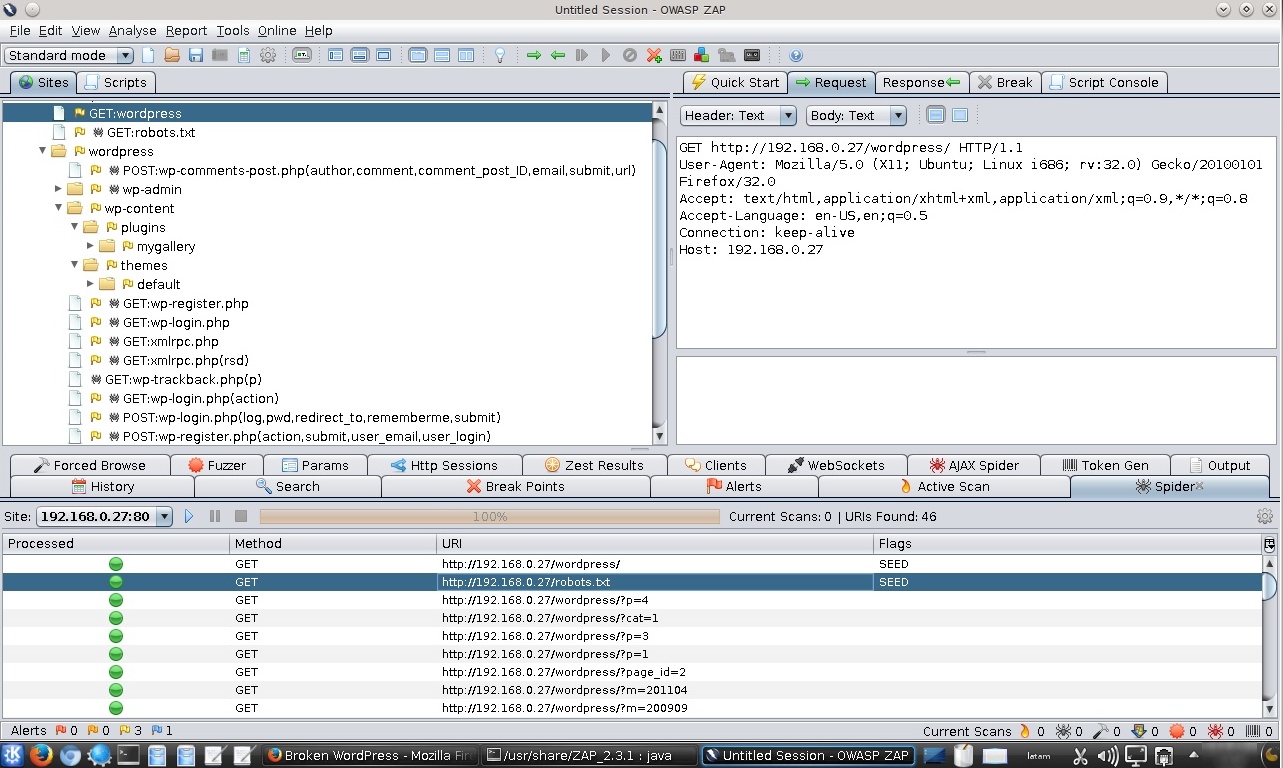
Diversas herramientas pueden realizar un Spidering automático de sitios web. Todas estas herramientas funcionan solicitando una página web, interpretándola por enlaces u otros contenidos, para luego solicitar estos enlaces, y continuando recursivamente hasta que no haya nuevo contenido descubierto.
Fuentes:
https://code.google.com/p/zaproxy/wiki/HelpStartConceptsSpider
https://code.google.com/p/zaproxy/wiki/HelpUiDialogsOptionsSpider
https://code.google.com/p/zaproxy/
http://www.odata.org/
http://atomenabled.org/
Sobre el Autor

Alonso Eduardo Caballero Quezada - ReYDeS
Instructor y Consultor Independiente en Ciberseguridad
Correo Electrónico: ReYDeS@gmail.com
Twitter: https://twitter.com/Alonso_ReYDeS
LinkedIn: https://pe.linkedin.com/in/alonsocaballeroquezada/
Facebook: https://www.facebook.com/alonsoreydes
Youtube: https://www.youtube.com/c/AlonsoCaballero
