
Web Robots
Web Robots; o Robots de la Web, también conocidos como Web Wanderes, Crawlers, o Spiders; son programas que atraviesan la web de manera automática. Los motores de búsqueda como Google los utiliza para indexar contenido web, los spammers lo utilizan para escanear direcciones de correo electrónico, y tienen otros usos variados.
Archivo /robots.txt
Los propietarios de sitios webs utilizan el archivo /robots.txt para dar instrucciones sobre sus sitios web a los robots; esto es llamado El Protocolo de Exclusión de Robots.
Utilizar cualquier navegador para acceder al archivo robots.txt.
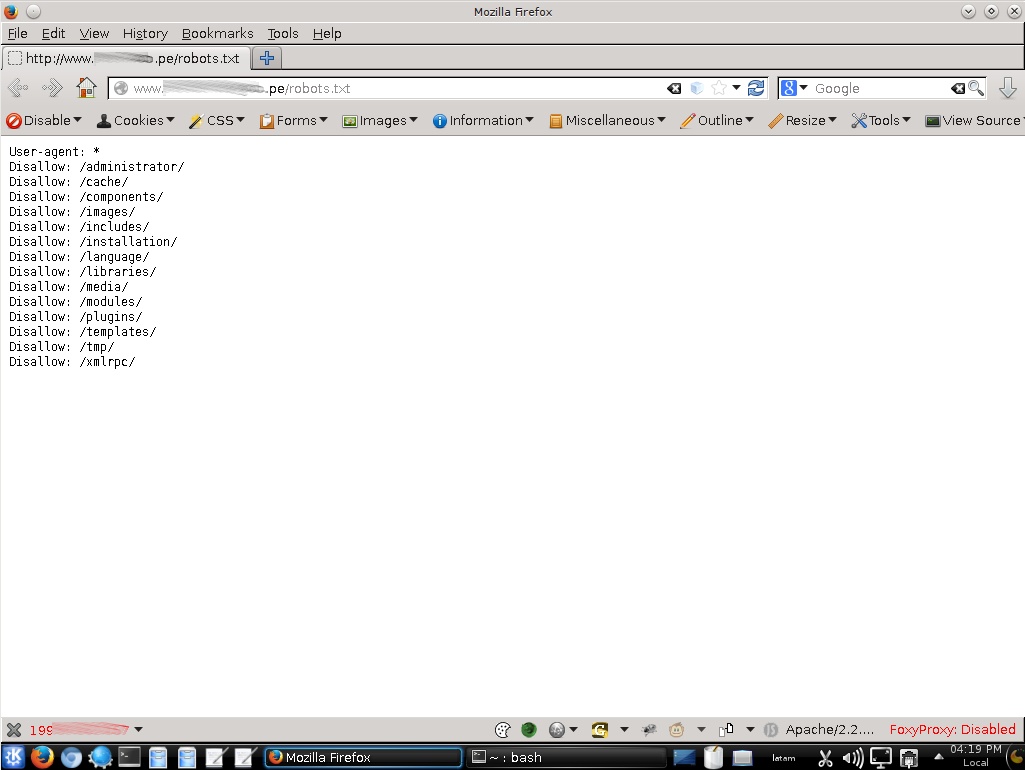
Esto funciona de la siguiente manera, un robot desea visitar el sitio web http : // abcdef . com/ index .html Antes de hacer esto, primero verifica el archivo robots.txt.
“User-agent: *” significa que esta sección se aplica a todos los robots. “Disallow: /directorio” le indica al robot que este directorio no debe ser visitado en el sitio.
Existen dos importantes consideraciones cuando se utilice el archivo /robots.txt
- Los robots pueden ignorar el archivo /robots.txt. Especialmente robots de malware que escanean la web por vulnerabilidades, y cosechadores de direcciones de correo electrónico utilizados por los spammers.
- El archivo robots.txt es un archivo disponible públicamente. Cualquiera puede visualizar cuales son las secciones del servidor que no se desea que los robots utilicen. Así es que este archivo no se debe ser utilizarlo para ocultar información.
Se utiliza la herramienta wget para obtener un nuevo archivo robots.txt. En el archivo se indica en su primera sección que todos los robots están permitidos de visitar todo el sitio web. Y en la segunda sección se le indica explícitamente al robot de Google que puede visitar todo el sitio web.
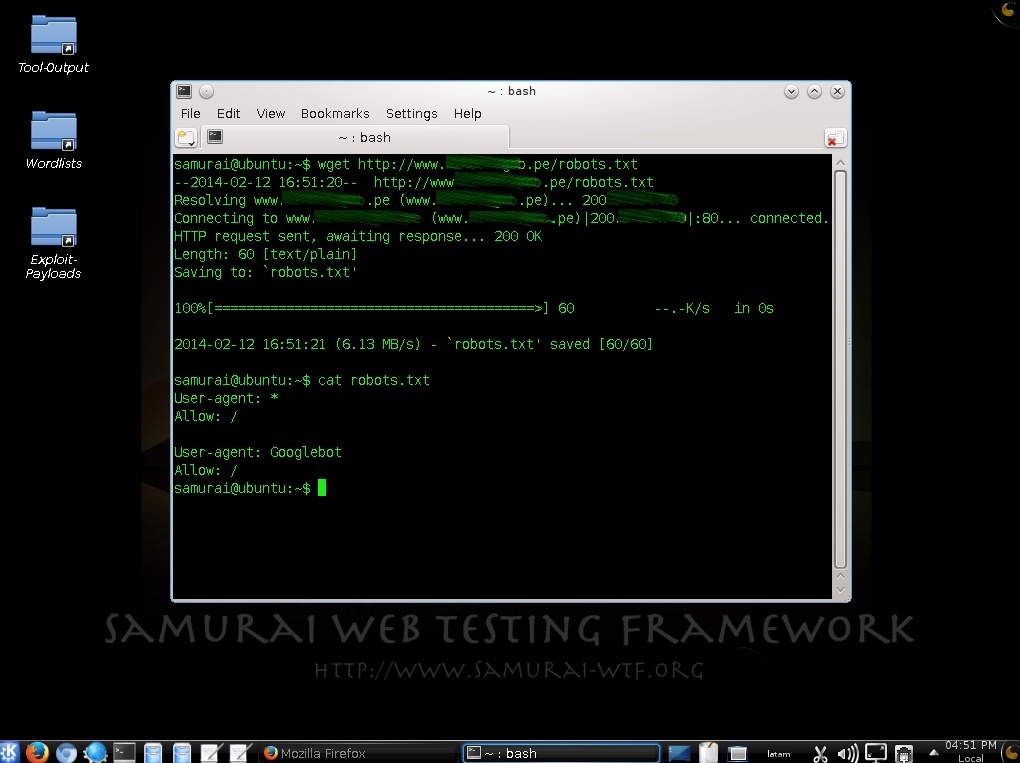
En una Prueba de Penetración este archivo puede exponer información sobre rutas de carpetas o directorios. De esta manera se empieza a conocer la estructura de una aplicación web. Sin un conocimiento profundo sobre la disposición de una aplicación web, es poco probable que se pueda realizar una prueba óptima.
Fuentes:
http://www.robotstxt.org/
https://www.owasp.org/index.php/Testing:_Review_Webserver_Metafiles_for_...
https://github.com/cmlh/rockspider
Sobre el Autor

Alonso Eduardo Caballero Quezada - ReYDeS
Instructor y Consultor Independiente en Ciberseguridad
Correo Electrónico: ReYDeS@gmail.com
Twitter: https://twitter.com/Alonso_ReYDeS
LinkedIn: https://pe.linkedin.com/in/alonsocaballeroquezada/
Facebook: https://www.facebook.com/alonsoreydes
Youtube: https://www.youtube.com/c/AlonsoCaballero
