Control de Robots
Las herramientas automáticas para realizar Spidering se conocen como "robots". Estos son frecuentemente utilizados por los motores de búsqueda, como Google, Bing, o Yandex, para generar una base de datos de las páginas disponibles en la Web. Los robots también pueden ser utilizados por los administradores del sitio web para verificar la validez de los enlaces, por spammers para recolectar direcciones de correo electrónico, o para otros propósitos.
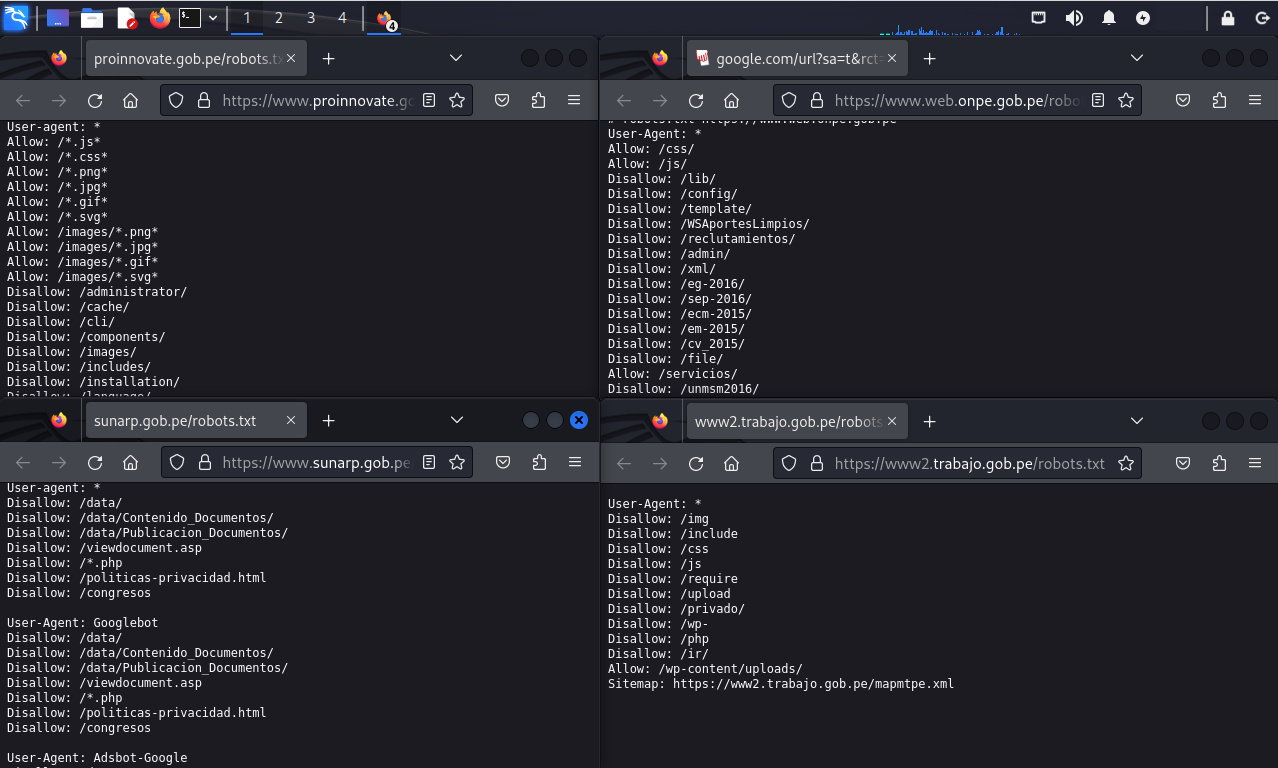
El Protocolo para la exclusión de robots es un estándar no oficial y de uso común, el cual permite a los administradores de sitios web especificar cuales áreas los robots no deben rastrear. Los administradores simplemente crean un archivo de nombre “robots.txt” en el directorio raíz del sitio web, para luego enumerar en este los directorios y páginas los cuales no deben ser rastreados. Muchos robots; incluido el rastreador de Google; buscan este archivo y actúan en consecuencia. Sin embargo los robots pueden ignorar este archivo, y también puede ser útil para los ciberatacantes porque proporciona una lista conveniente de páginas y directorios para los cuales los administradores no quieren se acceda ampliamente.
Los administradores de sitios web también pueden utilizar la etiqueta META de HTML Robots para indicar aquello los robots no deben ver una página en particular. Sin embargo este método no es de uso común.
De manera alterna a “Robots” se pueden utilizar meta etiquetas (meta tags) sobre páginas individuales.
Las etiquetas (tags) para prevenir el contenido esté en caché son:
<META HTTP-EQUIV="PRAGMA" CONTENT="NO-CACHE">
<META HTTP-EQUIV="CACHE-CONTROL" CONTENT="NO-CACHE">
Estos dos primeros deben utilizarse pues diferentes clientes respetan cada uno de estos.
Las etiquetas (tags) para controlar los spiders de motores de búsqueda y hacia donde irán son:
<META NAME="ROBOTS" CONTENT="INDEX,NOFOLLOW">
<META NAME="GOOGLEBOT" CONTENT="NOARCHIVE">
Estas dos son útiles para controlar los bots correspondientes a los motores de búsqueda.
Fuentes:
Sobre el Autor

Alonso Eduardo Caballero Quezada - ReYDeS
Instructor y Consultor Independiente en Ciberseguridad
WhatsApp: https://wa.me/51949304030
Correo Electrónico: ReYDeS@gmail.com
Twitter: https://twitter.com/Alonso_ReYDeS
Youtube: https://www.youtube.com/c/AlonsoCaballero
LinkedIn: https://pe.linkedin.com/in/alonsocaballeroquezada/