
Revisar Meta Archivos de Servidores Web por Fuga de Información
Aquí se describe como evaluar el archivo de nombre “robots.txt, por fuga de información sobre las rutas de carpetas o directorios de la aplicación web. Además, la lista de directorios a ser evitados por los “Spiders”, “Robots” o “Crawlers”, pueden también ser creados como una dependencia para mapear las rutas de ejecución a través de la aplicación web.
Objetivo de la Prueba
1. Fuga de información del directorio o rutas de carpetas de la aplicación.
2. Crear una lista de directorios a ser evitados por los Spiders, Robots, o Crawlers.
Como Evaluar
robots.txt
Los Spiders Web, Robots, o Crawlers capturan una página web, y luego de manera recursiva atraviesan hiperenlaces para obtener contenido web más profundo. Su comportamiento aceptado está especificado por el “Robots Exclusion Protocol”, en el archivo de nombre “robots.txt” ubicado en el directorio web raíz.
Un ejemplo del archivo “robots.txt” obtenido desde una aplicación web.
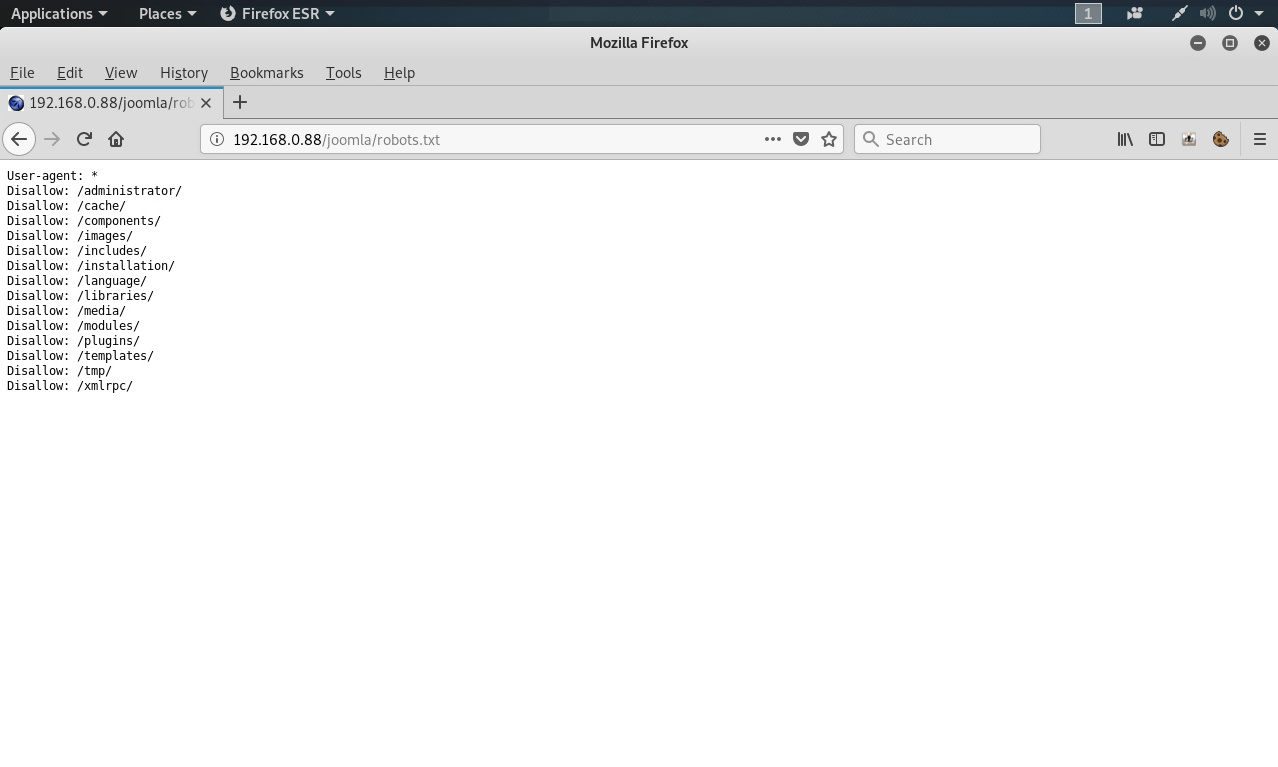
La directiva “User-agent: *” refiere hacia un específico spider, robot o crawler. Por ejemplo un “User-Agent: Googlebot” refiere al spider de Google, mientras un “User-Agent: bingbot” refiere hacia un crawler de Microsoft. En este caso “User-Agent: *” aplica a todos los spiders, robots, o crawlers.
La directiva “Disallow” especifica cuales recursos están prohibidos para los spiders, robots y crawlers.
Los spiders, robots o crawlers pueden intencionalmente ignorar las directivas “Disallow” en un archivo “robots.txt”, tales como aquellos pertenecientes a redes sociales, para asegurarse los enlaces compartidos son válidos. Por lo tanto el archivo “robots.txt” no puede ser considerado como un mecanismo para fortalecer las restricciones sobre como el contenido web es accedido, almacenado, o nuevamente publicado por terceros.
El archivo robots.txt en la raíz web con “wget” o “curl”
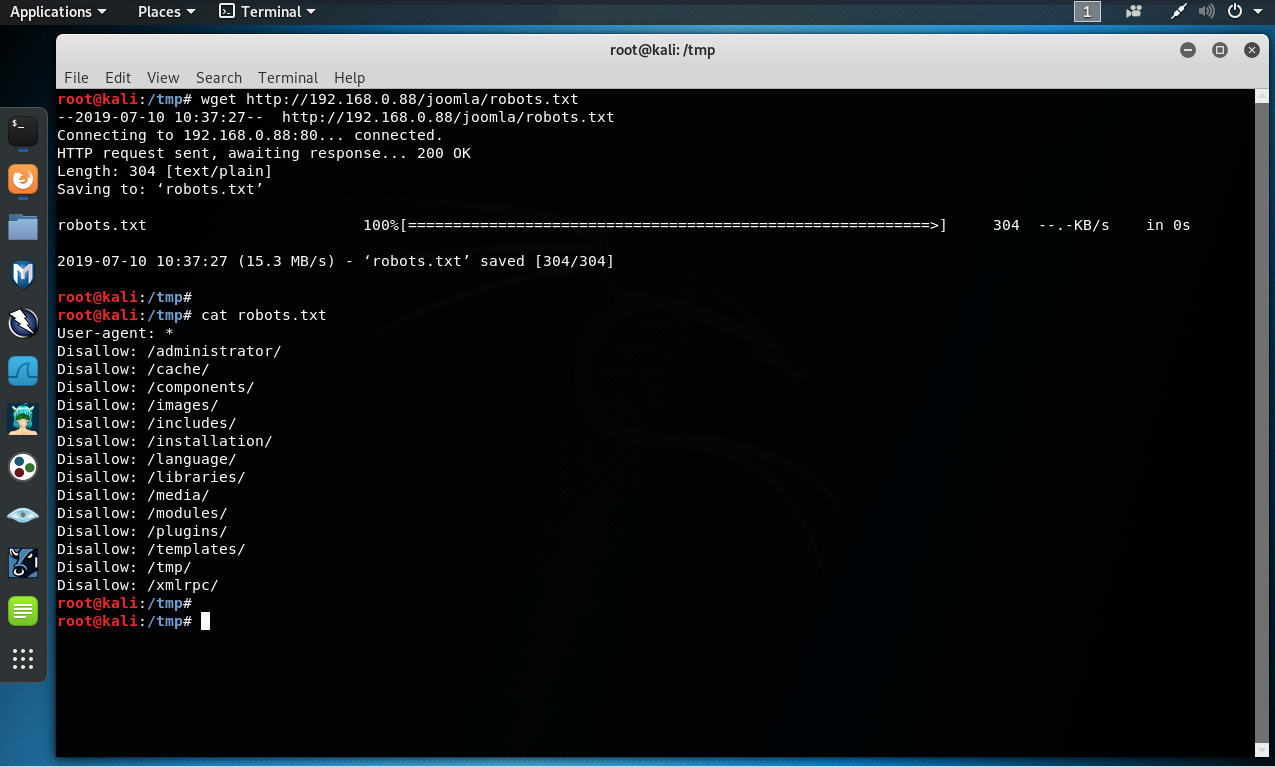
El archivo “robots.txt” es obtenido desde el directorio web raíz del servidor web, como también de un subirectorio donde reside la aplicación web. Para esto se pueden utilizar las herramientas “wget” o “curl”.
# wget http://192.168.0 .88/joomla/robots.txt
# cat robots.txt
# curl -O http://192.168. 0.88/joomla/robots.txt
# cat robots.txt
Analizar el archivo “robots.txt” utilizando Google
Los propietarios de los sitios web pueden utilizar la función para analizar el archivo “robots.txt” de Google, la cual es parte de “Google Webmaster Tools”. Esta herramienta puede ayudar con la evaluación.
Etiquetas META
Las etiquetas <META> están ubicadas dentro de la sección HEAD de cada documento HTML, y deben ser consistentes a través de todo el sitio web, en el evento probable del punto de partida de un robot, spider o crawler no inicie desde un enlace a un documento aparte de la web raíz, como un enlace profundo.
Si no existe una entrada “<META NAME=ROBOTS”… >”, entonces el “Robots Exclusion Protocol” tendrá por defecto respectivamente “INDEX,FOLLOW”. Por lo tanto las otras entradas válidas definidas por el “Robots Exclusion Protocol” serán prefijadas con “NO...”, es decir “NOINDEX,NOFOLLOW”
Los spiders, robots o crawlers pueden intencionalmente ignorar la etiqueta “<META NAME=”ROBOTS”>”, pues se prefiere la conversión del archivo “robots.txt”. Por lo tanto las etiquetas “<META>” no deben ser consideradas el mecanismo principal, sino un control complementario al archivo “robots.txt”.
Etiquetas < META > con Zed Attack Proxy
Basados en las directivas “Disallow” listadas dentro del archivo “robots.txt” en la raíz web, se realiza una búsqueda utilizando expresiones regulares para “<META NAME=”ROBOTS”>", dentro de cada página web, y el resultados se compara con el archivo “robots.txt”.
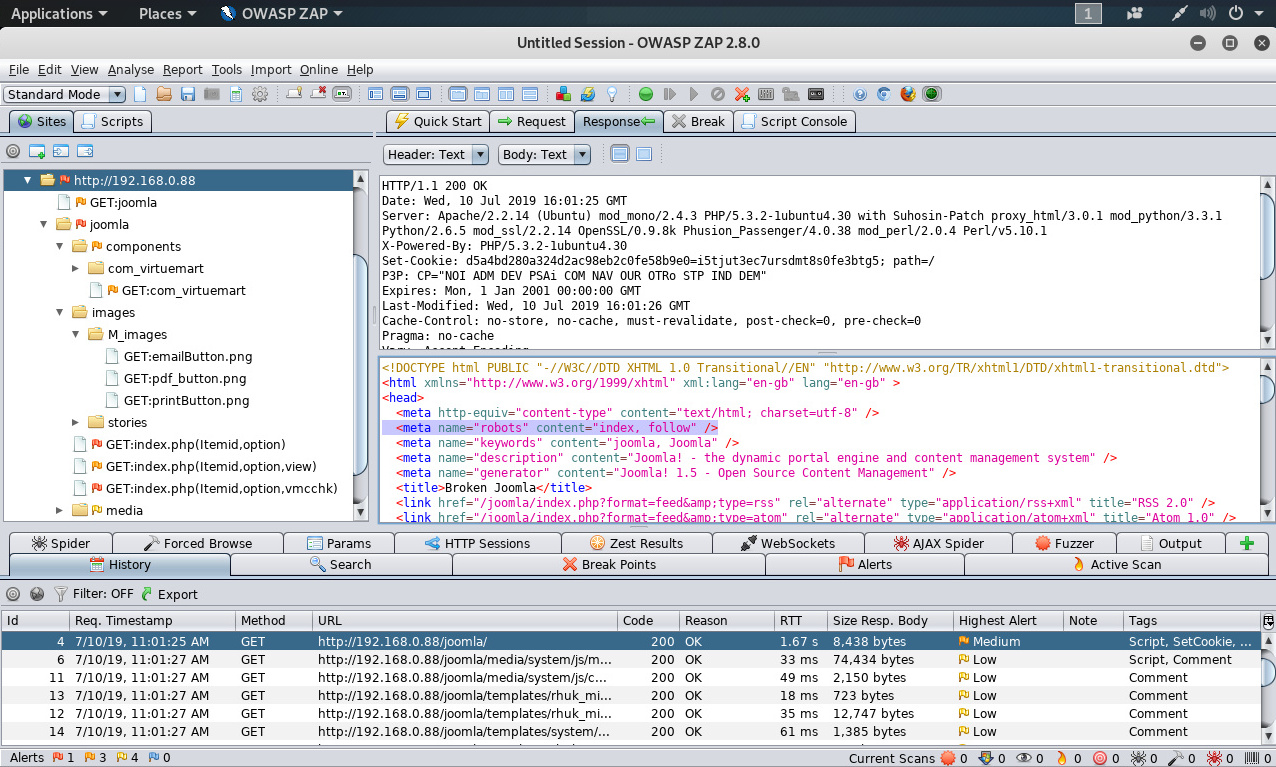
La anterior imagen siguiente etiqueta <META> está definida a “INDEX.FOLLOW”.
Fuentes:
https://www.owasp.org/index.php/Review_Webserver_Metafiles_for_Informati...(OTG-INFO-003)
https://www.robotstxt.org/
https://www.gnu.org/software/wget/
https://curl.haxx.se/
https://www.google.com/webmasters/tools/robots-testing-tool
https://github.com/zaproxy/zaproxy
Sobre el Autor

Alonso Eduardo Caballero Quezada - ReYDeS
Instructor y Consultor Independiente en Ciberseguridad
Correo Electrónico: ReYDeS@gmail.com
Twitter: https://twitter.com/Alonso_ReYDeS
LinkedIn: https://pe.linkedin.com/in/alonsocaballeroquezada/
Facebook: https://www.facebook.com/alonsoreydes
Youtube: https://www.youtube.com/c/AlonsoCaballero
