html2dic
html2dic extrae todas las palabras desde una página HTML, generando un diccionario de todas las páginas encontradas, una por línea. El resultados en impreso a través de las salida estándar.
El diccionario generado luego puede ser utilizado para un ataque por diccionario. Este ataque implica intentar todas las posibles cadenas de un listado previamente establecida. Estos ataques originalmente utilizaban las palabras encontradas en un diccionario, sin embargo ahora existen listas mucho más grandes disponibles en Internet, conteniendo cientos de millones de contraseñas recuperadas de filtraciones expuestas.
Se procede a descargar un archivo html.
$ wget con greso. gob. pe
Se utiliza la herramienta html2dic para volcar un diccionario de palabras desde un archivo html de entrada. El resultado se redirecciona hacia el archivo de nombre “wordlist.txt”
$ html2dic index.html > wordlist.txt
Al archivo resultante se le aplican algunos filtros, como ordenar la lista de palabras utilizando comando “sort”, eliminar las lineas duplicadas utilizando el comando “uniq”. Luego se utiliza la herramienta pw-inspector para únicamente mostrar las palabras con una longitud mínima de 6 caracteres y una longitud máxima de 16 caracteres.
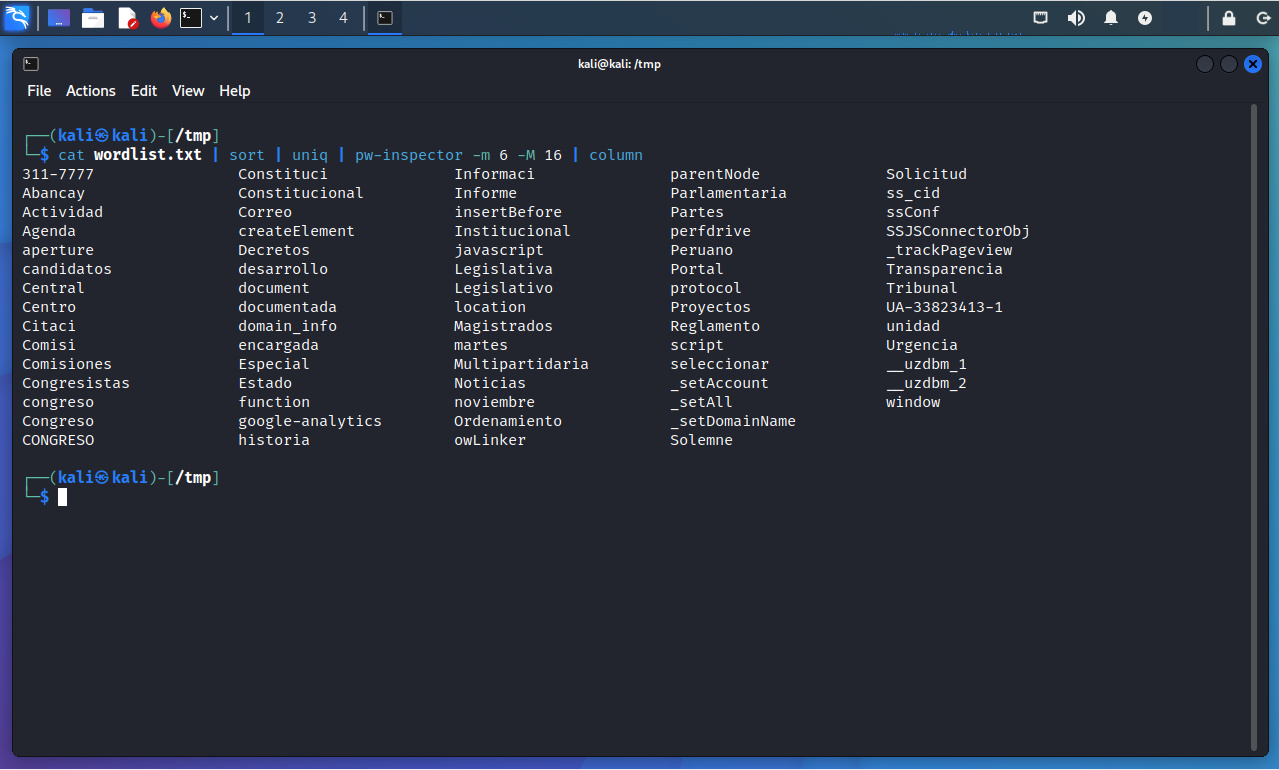
$ cat wordlist.txt | sort | uniq | pw-inspector -m 6 -M 16 | column
El contenido del archivo es mostrado en columnas, dado el hecho se está utilizando el comando “column”.
Fuentes:
https://dirb.sourceforge.net/
https://salsa.debian.org/pkg-security-team/dirb
https://github.com/vanhauser-thc/thc-hydra/blob/master/pw-inspector.c
Sobre el Autor

Alonso Eduardo Caballero Quezada - ReYDeS
Instructor y Consultor Independiente en Ciberseguridad
WhatsApp: https://wa.me/51949304030
Correo Electrónico: ReYDeS@gmail.com
Twitter: https://twitter.com/Alonso_ReYDeS
Youtube: https://www.youtube.com/c/AlonsoCaballero
LinkedIn: https://pe.linkedin.com/in/alonsocaballeroquezada/