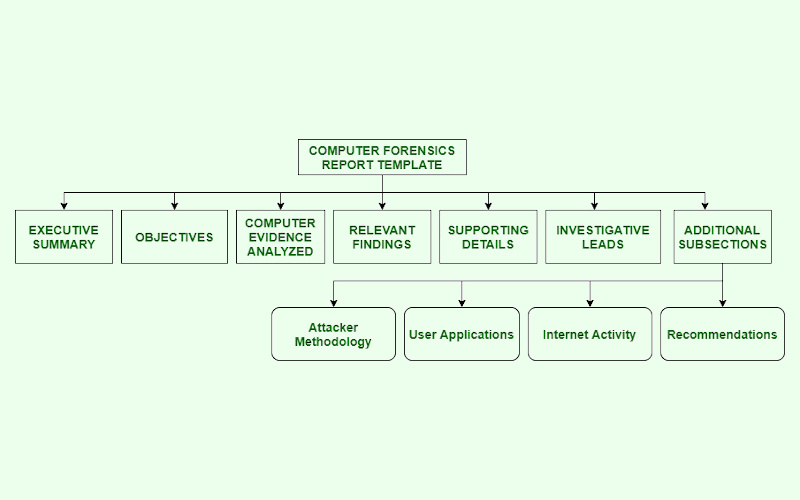
dpl4hydra
dpl4hydra genera una lista de contraseñas por defecto como entrada para la herramienta THC-Hydra.
Este script permite generar listas con las contraseñas por defecto de los principales proveedores de dispositivos de red como; 2wire, 360systems, 3com, 3m, acc, acceleratednetworks, accton, aceex, acer, actiontec, adaptecraid, adc, adckentrox, adcompleteco, adic, adp, adtech, adtran, advanced, advanteknetworks, aethra, airlink, aironet, aladdin, alcatel, allied, allnet, allot, alteon, ambit, ami, amitech, amptron, amptron, andovercontrols, aoc, apache, apc, apple, areca, arescom, arlotto, arrow‐point, asante, ascend, ascom, asmack, asmax, aspect, ast, asus, at&t, atcom, atlantis, att, attachmate, audioactive, autodesk, avaya, avengernewssystem, award, axis, aztech, barracudanetworks, baynetworks, bea, beetal, belkin, bestpractical, betabrite, billion, bintec, biodata, biostar, bizdesign, blackbox, bluecoatsystems, bmc, borland, boson, boson, breezecom, broadlogic, brocade, brother, bt, buffalo, cableandwireless, cabletron, canyon, castlenet, cayman, celerity, cgi, cgiworld, chase, chaseresearch, checkpoint, chumingchen, ciphertrust, cisco, cnet, cobalt, colubrisnetworks, comersus, compaq, compex, compualynx, computer, comtrend, conceptronic, concord, conexant, conitec, corecess, coyotepoint, crystalview, ctx, cyberguard, cybermax, cyclades, d-link, daewoo, dallas, dallassemiconductors, darkman, data, datacom, datageneral, datawizard, davox, daytek, debian, decnet, deerfield, dell, demarc, deutschetelekom, develcon, dictaphone, digicom, digicorp, digicraftsoftware, digiinternational, digital, digitalequipment, discar, dlink, draytek, drupal.org, dupont, dynalink, dynix, econ, edimax, efficientnetworks, elron, elsa, eminent, encad, enhydra, enox, enterasys, entrust, epox, ericsson, etech, everfocus, exindanetworks, extendedsystems, extremenetworks, f5, firebird, flowpoint, fortinet, foundry, foundrynetworks, freetech, fujixerox, funk, funksoftware, galacticomm, gandalf, gateway, ge, geeklog, generalinstruments, gericom, giga, gigabyte, globespanvirata, gossamerthreads, grandstreamnetworks, greatspeed, guardone, h2o, h2oproject, harris, hayes, hewlett-packard, honeywell, horizondatasys, hosting, hp, huawei, ibm, imperiasoftware, informix, infosmart, infotec, infrant, innovaphone, integratednetworks, intel, interbase, intermec, intershop, intex, intuit, ipstar, ipswitch, irc, ironport, iso, iwill, jd, jdedwards, jds, jetform, jetway, johnsoncontrols, josstechnology, juniper, justin, justinhagstrom, kalatel, kaptest, kethinov, keyscan, konicaminolta, kti, kyocera, lacie, lanier, lantronics, leading, lenel, level1, lg, lgic, linksys, linux, livingstone, logitech, longshine, lucent, machspeed, macromedia, magic-pro, main, mambo, mantis, marconi, mcafee, mediatrix, megastar, memotec, mentec, mercury, metro, michiel, microcom, micron, micronet, micronics, microplex, microrouter, microsoft, mikepeters, mikrotik, minoltaqms, mintel, mitel, mobotix, motorola, mp3mystic, mro, mrv, multitech, mutaresoftware, muze, mysql, nai, nanoteq, ncr, netapp, netcomm, netgear, netgenesis, netopia, netport, netscape, netscreen, network, networkassociates, networkice, nexland, next, ngsec, ngsecure, nicesystemsltd, nimble, no, nokia, norstar, nortel, networkassociates, networkice, nexland, next, ngsec, ngsecure, nicesystemsltd, nimble, no, nokia, norstar, nortel, novell, nrg, nullsoft, nurit, oce, ods, oki, olicom, olitec, omnitronix, oodiecom, openconnect, openmarket, openwave, openxchange, optivision, optus, oracle, osicom, ovislink, pacific, packardbell, panasonic, pandatel, patton, penril, pentagram, pentaoffice, pentasafe, philips, phoenix, phpreactor, phptest, pirelli, planet, pollsafe, polycom, postgresql, prestige, prestigio, primebase, prolite, promise, prostar, proxim, pyramidcomputer, qdi, quake, qualiteam, quantex, quantum, radio, radioshack, radware, rainbow, rampnetworks, rapidstream, raritan, raytalk, redhat, redline, remedy, research, resumix, ricoh, rizen, rm, roamabout, rodopi, safecom, sagem, sambartechnologies, samsung, samuelabels, sap, sap, schneider, schneiderelectric, scientificatlanta, seagullscientific, securicor3net, securstar, semaphore, servertechnology, sgi, sharp, shiva, shoretel, shuttle
Se ejecuta dpl4hydra con la opción “help”, lo cual muestra un resumen de sus breves opciones.
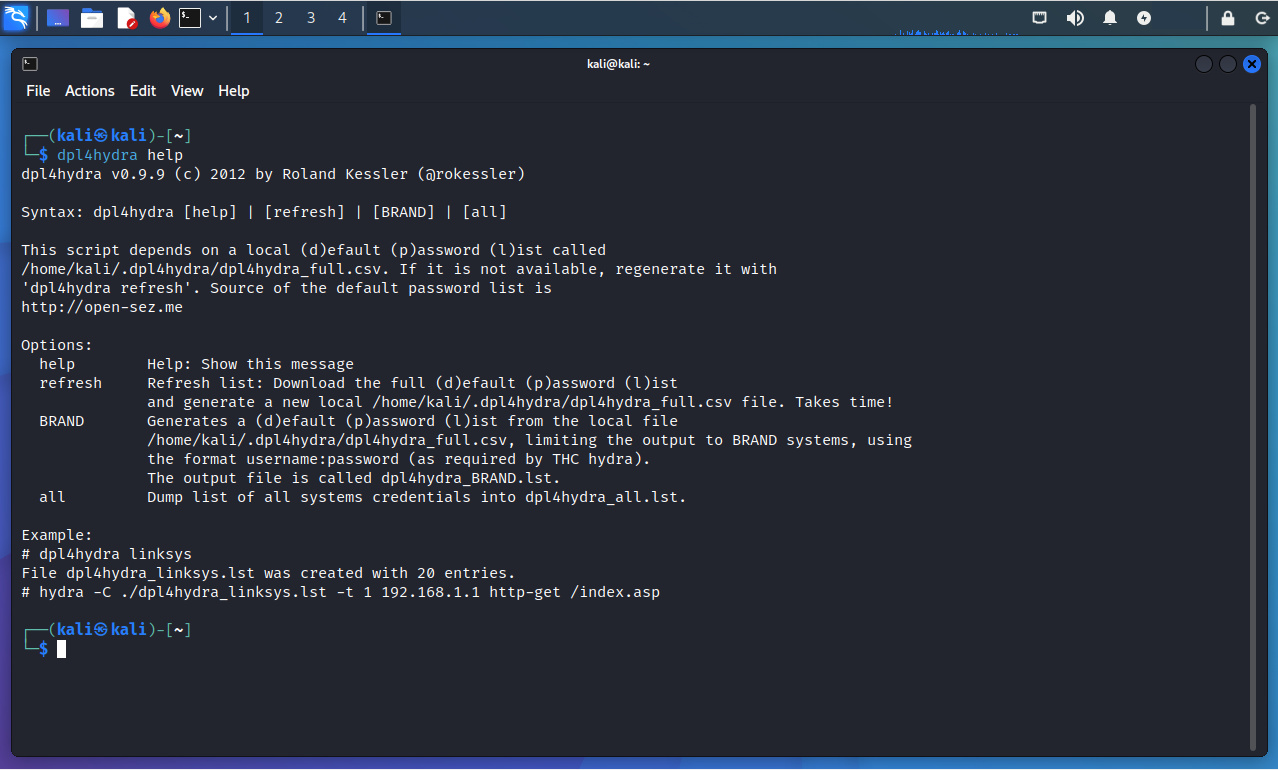
$ dpl4hydra help
La opción “BRAND” genera un lista de contraseñas por defecto desde “~/.dpl4hydra/dpl4hydra_full.csv”, limitando la salida hacia los sistema de tal MARCA, utilizando el formato nombredeusuario:contraseña (como lo requiere THC-Hydra).
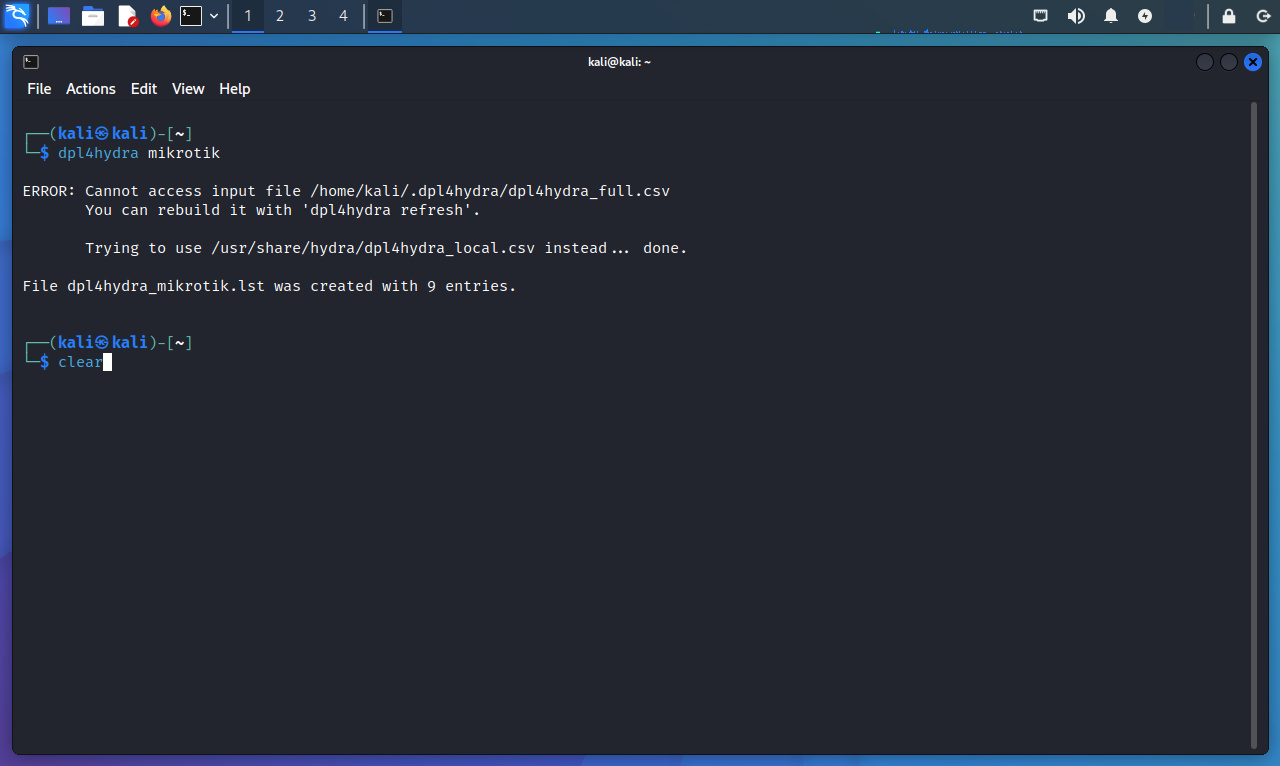
$ dpl4hydra mikrotik
El mensaje mostrado versa sobre la no posibilidad de acceder al archivo de entrada “/home/kali/.dpl4hydra/dpl4hydra_full.csv”.
Indicando debe ser nuevamente construida ejecutando el comando “dpl4hydra refresh”.
Este script depende de una lista local de contraseñas por defecto denominada “~/.dpl4hydra/dpl4hydra_full.csv”. Si no está disponible, se puede generarla nuevamente con dpl4hydra refresh. La fuente de la lista de contraseñas por defecto se menciona al final de la presente publicación.
Se ejecuta el comando indicado.
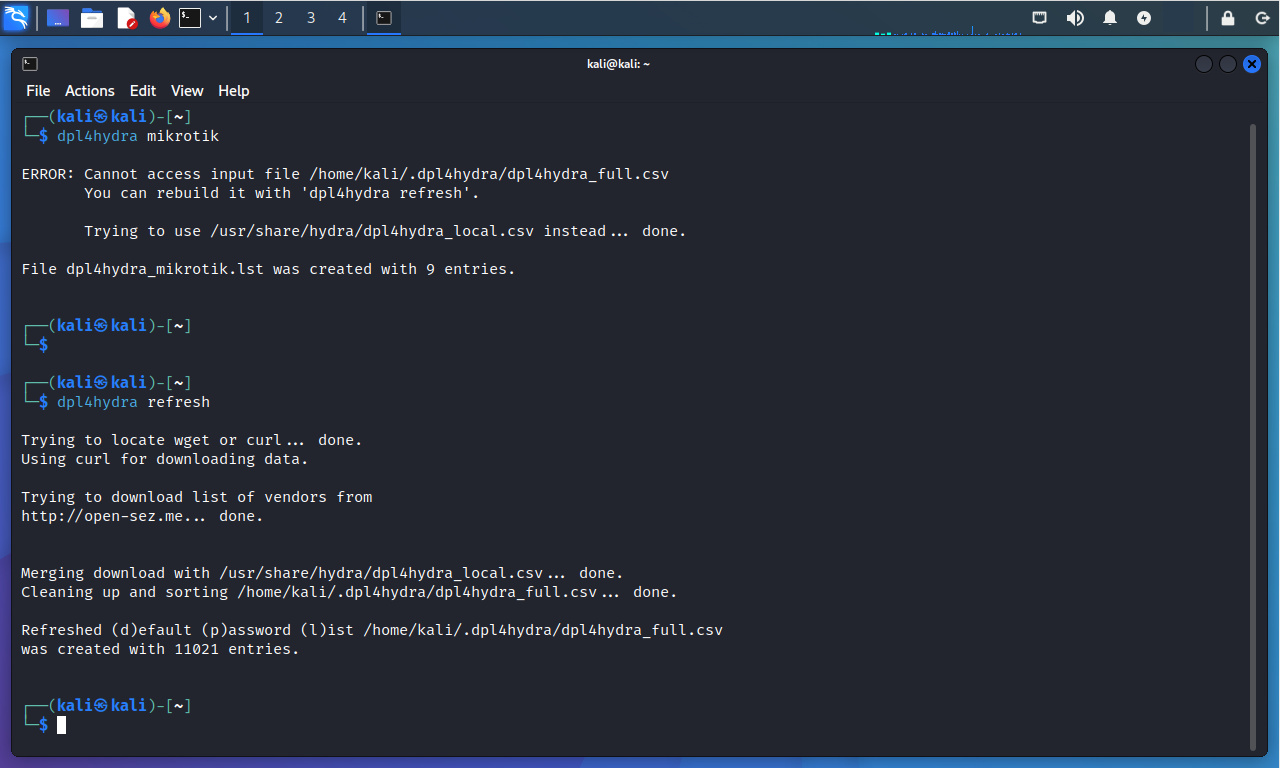
$ dpl4hydra refresh
Se procede nuevamente a ejecutar el comando para obtener un lista de contraseña por defecto para la MARCA mikrotik.
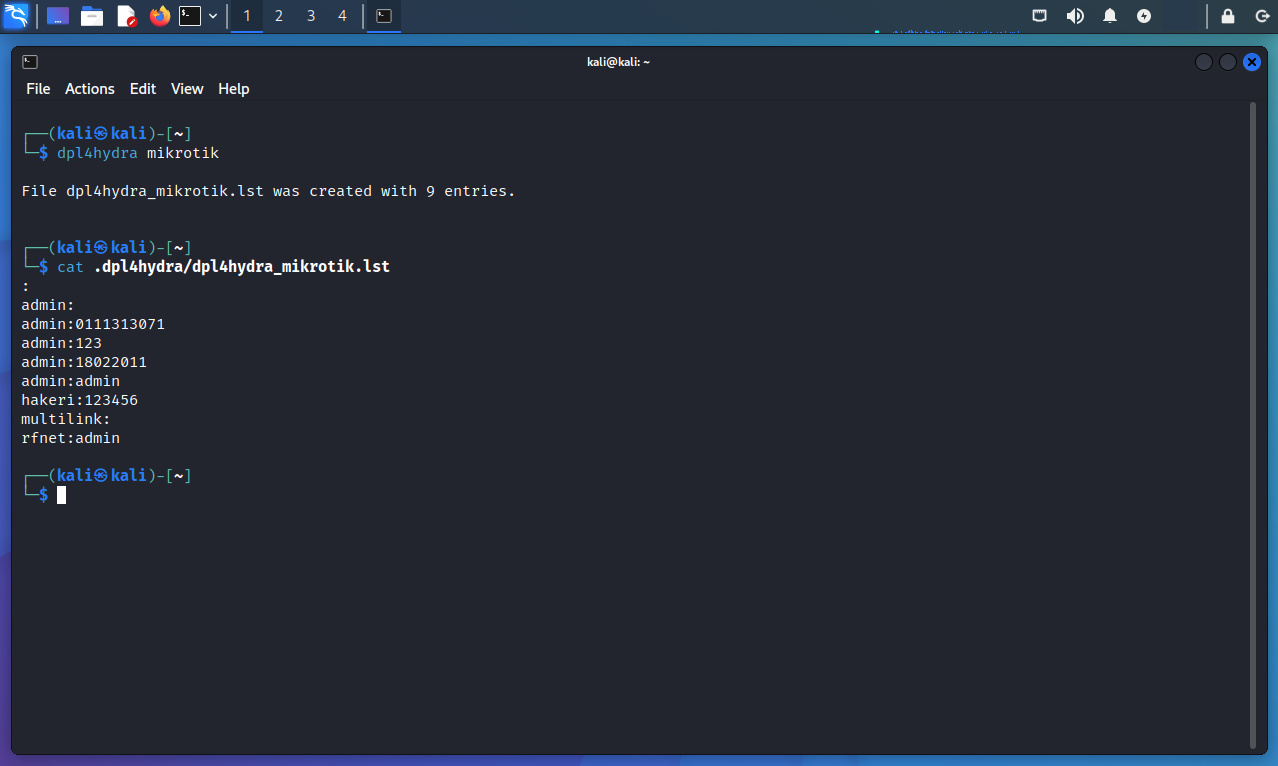
$ dpl4hydra mikrotik
$ cat .dpl4hydra/dpl4hydra_mikrotik.lst
Al visualizar en archivo se puede encontrar un listado de nombres de usuario y contraseñas por defecto separados por “dos puntos”.
Fuentes:
https://github.com/vanhauser-thc/thc-hydra
https://github.com/vanhauser-thc/thc-hydra/blob/master/dpl4hydra.sh
https://open-sez.me/index.html