Entender la Arquitectura de un Sistema
Diseño Conceptual
Es un diseño de alto nivel, el cual incluye los componentes fundamentales para una arquitectura de red. Esta vista abstraída proporciona al profesional en ciberseguridad, una imagen comprensible sobre el propósito global de la red, y porque la solución fue diseñada de esta manera. El diseño conceptual incluirá los principales sistemas tecnológicos, cualquier sistema externo requerido para integración o funcionalidad general, flujo de datos, y comportamiento del sistema a alto nivel. Este método de diseño utiliza una perspectiva de diagramación “caja negra” para simplificar sistemas complejos en componente únicos con un rol o propósito general.

Diseño Lógico
Representa cada función lógica en el sistema. Es mucho más detallado y debe incluir todos los componentes principales en la red, además de sus relaciones. Los flujos de datos detallados y conexiones son también mapeados en el diseño lógico. Este diseño es creado principalmente para los desarrolladores y arquitectos en ciberseguridad. Los diseños lógicos incluyen servicios, nombres de aplicación, e información relevante de desarrollo, pero típicamente no incluye nombres de servidor o direcciones.
Diseño Físico
Incluye todos los principales sistemas y factores dentro de áreas previamente definidas de servidor. Este diseño físico es usualmente el último diseño creado antes de la implementación final, y puede ser utilizado como un recurso por el equipo de implementación final. Este nivel de diseño incluye el conocimiento sobre todos los detalles del sistema operativo, parches, y versiones. Cualquier restricción o limitación también son identificados dentro de componentes servidor, flujos de datos, o conexiones.
Entender el Flujo de Comunicación
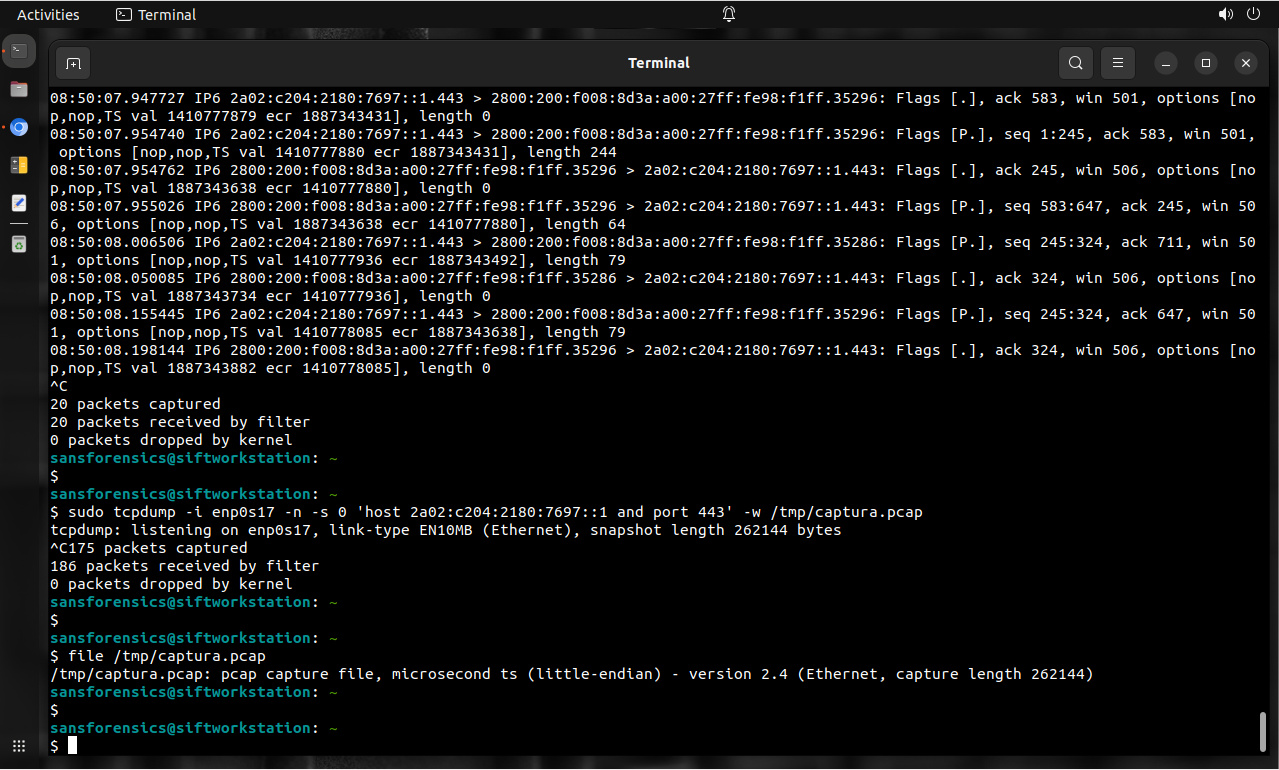
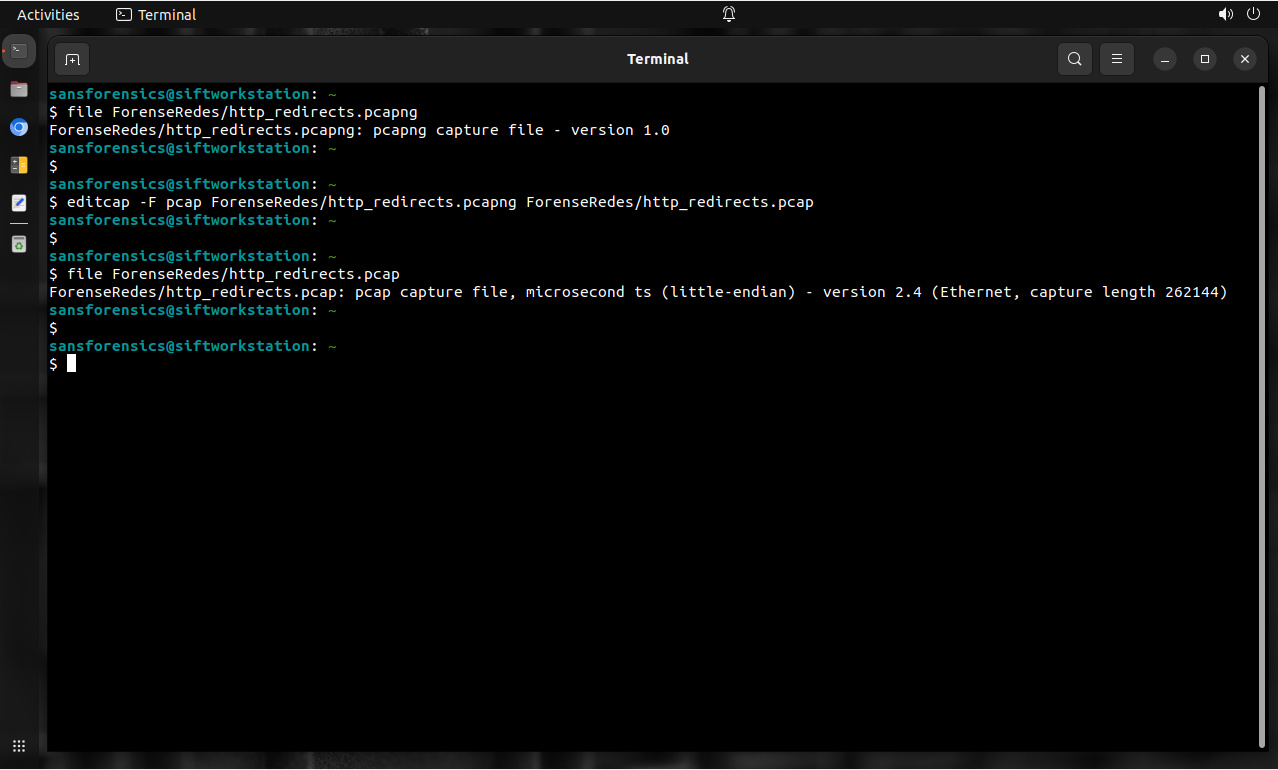
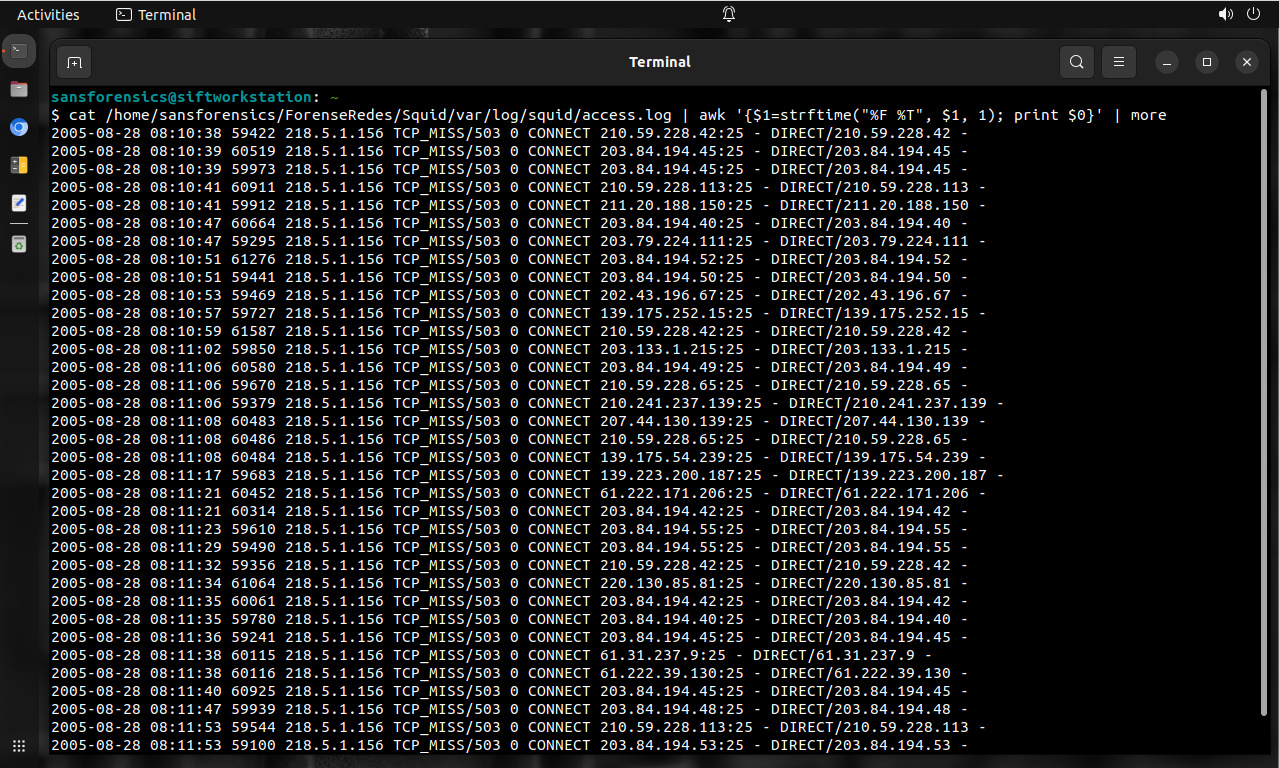
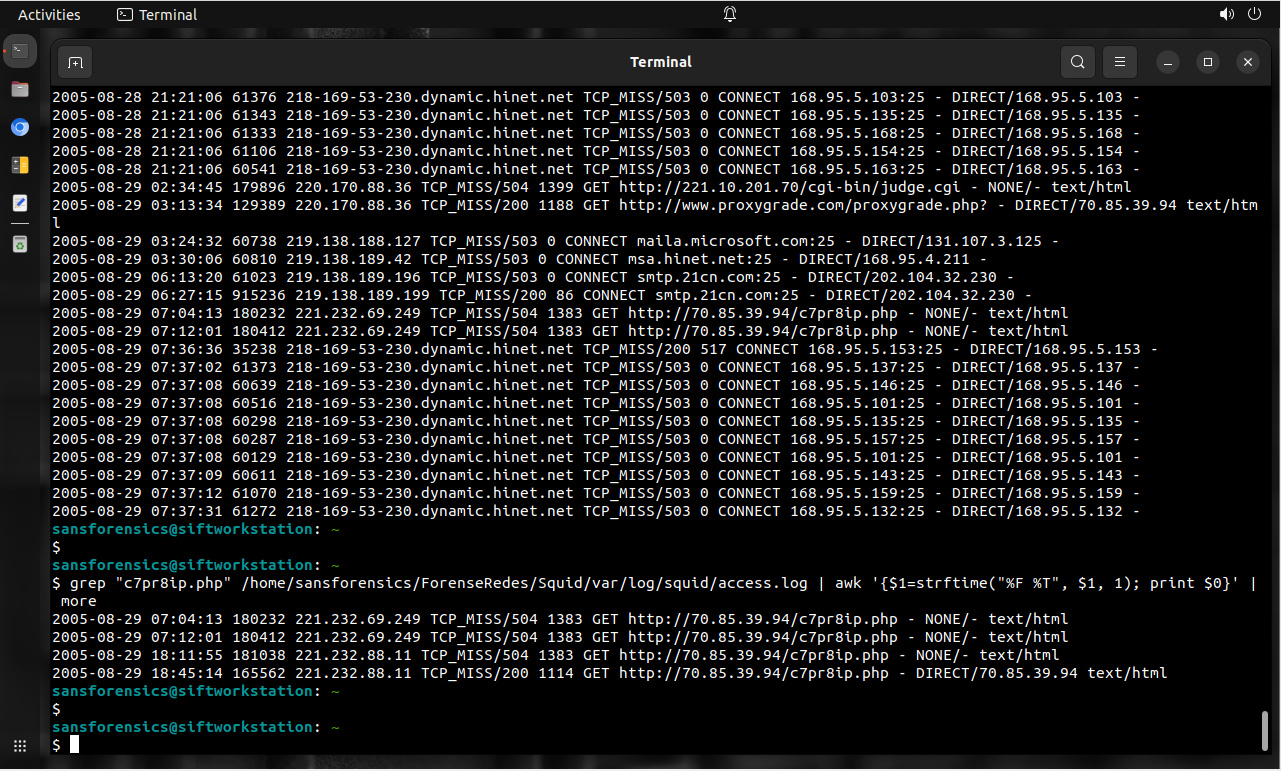
Inicia con la arquitectura lógica. Cada flujo de comunicación, ya sea para intercambio de datos o mensajes para control, debe ser diagramado sin importar su propósito.
Conocer el valor de los Datos
También inicia con la arquitectura lógica. Y así como se necesita para conocer cada flujo de comunicación, también se necesita conocer donde reside cada archivo y datos valiosos.
Fuentes: