Un servidor proxy como su nombre implica, es un servidor el cual está configurado para romper el tráfico de red entre un sistema cliente y un sistema servidor. Aunque los proxys pueden ser utilizados casi con cualquier protocolo o servicio de red, actualmente casi siempre se les identifica asociándolos con tráfico web utilizando los protocolos HTTP y HTTPS.
Originalmente los proxys fueron desarrollados para conservar ancho de banda sobre enlaces de red con baja velocidad. Por ejemplo: Un servidor proxy podría ser desplegado en el frente de cientos de clientes compartiendo una conexión de alta velocidad. En este caso el proxy podría recibir peticiones de los clientes por contenido web desde los sistemas residiendo fuera de la red, luego solicita tal contenido desde el servidor responsable de la URL, y proporciona lo solicitado hacia el sistema cliente. Por lo tanto el proxy podría mantener también una copia del contenido. Luego si otro cliente realiza la misma petición hacia la misma página poco tiempo después, el proxy podría simplemente proporcionar el contenido desde caché, sin solicitar nuevamente la página web utilizando la misma conexión de alta velocidad.
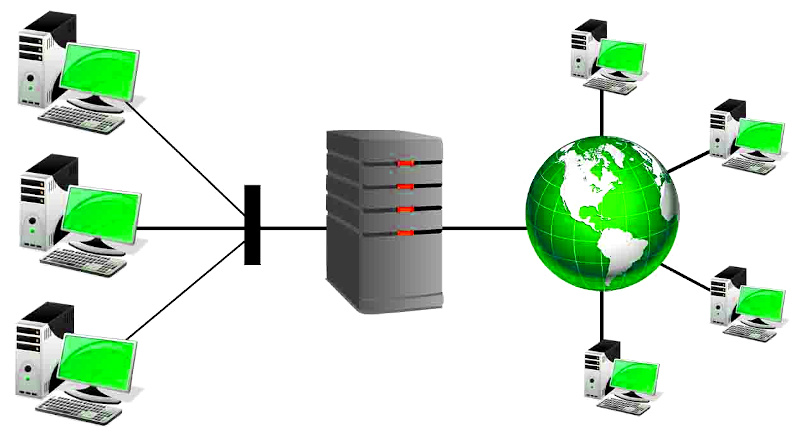
Los servidores proxy pueden también funcionan como “proxys reversos”. En este modelo los servidores proxy generalmente rompen la petición desde un gran número de sistemas cliente hacia un pequeño número de servidores. Frecuentemente un servidor proxy proporcionará balanceo de cargar, compresión, y otras funcionalidades para mejorar el desempeño.
La razón por la cual es importante abarcar los proxys, es a razón de proporcionan una visión muy útil sobre las actividades de red correspondientes a los usuarios y sistemas, con relación a ciertos protocolos como HTTP. Demostrar el uso de un proxy en un escenario típico de investigación, abarca diferentes disciplinas y tópicos sobre forense de redes.
Como con muchos dispositivos de infraestructura, el movimiento de seguridad también identifica valor en los datos residiendo en un servidor proxy. Los administradores de red pueden configurar los servidores proxy para bloquear contenido indeseable , previniendo los sistemas clientes accedan a contenido prohibido. Adicionalmente la naturaleza “portero” de los servidores proxy proporciona dos recursos vitales para los profesionales en seguridad de la información: Contenido de los logs con transacciones, y datos en caché.
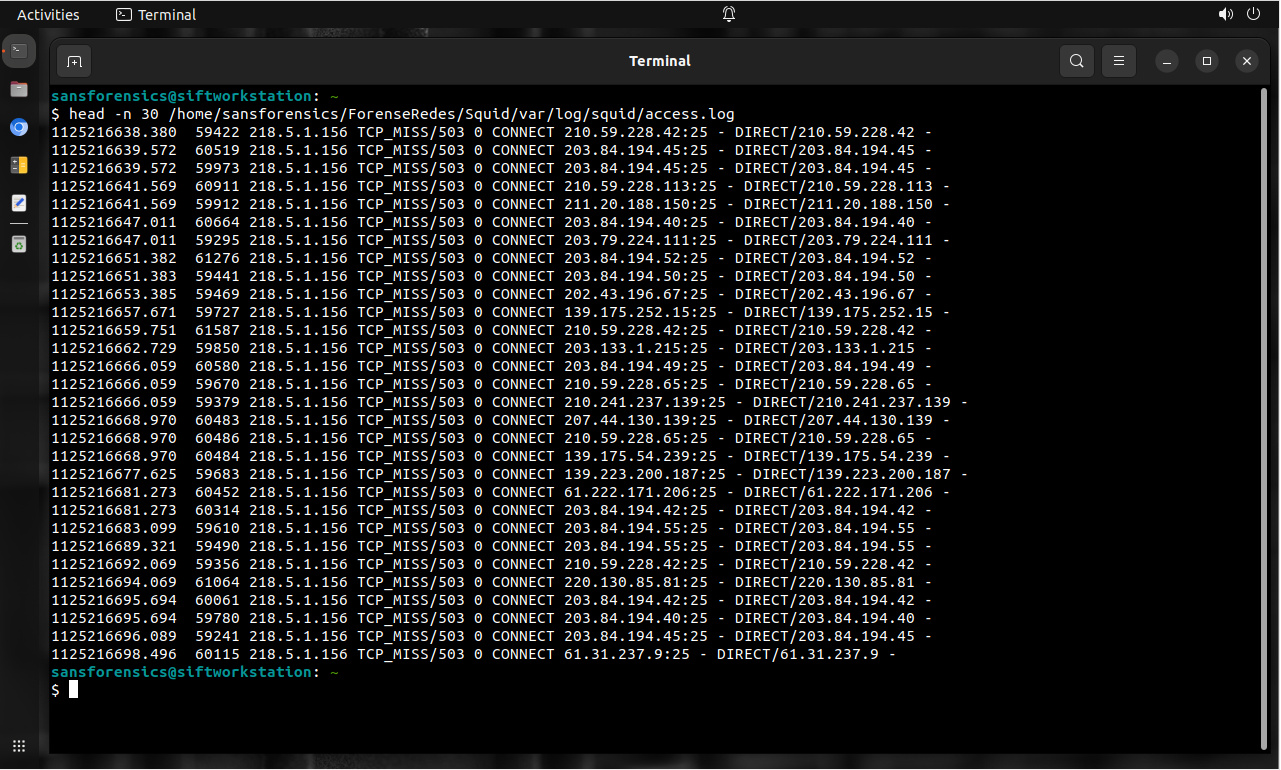
Los Logs creados por un servidor proxy web son invaluables para determinar cuales URLs fueron solicitados por los clientes. Esto puede (rápidamente) responder la pregunta: ¿Cuales sistemas internos intentaron acceder hacia sitios conocidos como maliciosos o descargas?. Ya sea se investigue un incidente de phishing o una botnet utilizando HTTP para comando y control, los logs del proxy pueden establecer el alcance de un incidente mucho más rápido, comparado con aquello lo cual un análisis sistema por sistema podría alguna vez hacer.
Además el propósito de un servidor proxy cache es mantener copias de recursos obtenidos por sistemas clientes, significando los equipos de seguridad pueden obtener estos objetos desde cache para un análisis posterior, sin incluso deber poner los dedos en el teclado de un sistema cliente infectado. Si alguna vez se debió examinar un sistema comprometido el cual no contiene una pieza del malware descargado, se apreciará la belleza de esta opción.
La naturaleza proactiva de un servidor proxy, puede también ayudar durante el proceso para respuesta ante incidentes. Un administrador puede reconfigurar una red adecuadamente implementada y un servidor proxy para bloquear tráfico HTTP malicioso. Esta puede ser alcanzado casi instantáneamente desde un punto central para toda la empresa. En una situación donde la velocidad y la decisión es crítica, un servidor proxy proporciona un valor inconmensurable para el proceso de respuesta ante incidentes.
Fuentes:
https://forensics.wiki/proxy_server/